
The real research behind the wild rumors about OpenAI’s Q* project
OpenAI hasn't said what Q* is but it has revealed plenty of clues.

I’m a journalist with a computer science master’s degree. In the past I’ve written for the Washington Post, Ars Technica, and other publications.
Understanding AI explores how AI works and how it’s changing the world. If you like this article, please sign up to have future articles sent straight to your inbox.
On November 22, a few days after OpenAI fired (and then re-hired) CEO Sam Altman, The Information reported that OpenAI had made a technical breakthrough that would allow it to “develop far more powerful artificial intelligence models.” Dubbed Q* (and pronounced “Q star”) the new model was “able to solve math problems that it hadn’t seen before.”
Reuters published a similar story, but details were vague.
Both outlets linked this supposed breakthrough to the board’s decision to fire Altman. Reuters reported that several OpenAI staffers sent the board a letter “warning of a powerful artificial intelligence discovery that they said could threaten humanity.” However, “Reuters was unable to review a copy of the letter,” and subsequent reporting hasn’t connected Altman’s firing to concerns over Q*.
The Information reported that earlier this year OpenAI built “systems that could solve basic math problems, a difficult task for existing AI models.” Reuters described Q* as “performing math on the level of grade-school students.”
Instead of immediately leaping in with speculation, I decided to take a few days to do some reading. OpenAI hasn’t published details on its supposed Q* breakthrough, but it has published two papers about its efforts to solve grade-school math problems. And a number of researchers outside of OpenAI—including at Google’s DeepMind—have been doing important work in this area.
I’m skeptical that Q*—whatever it is—is the crucial breakthrough that will lead to artificial general intelligence. I certainly don’t think it’s a threat to humanity. But it might be an important step toward an AI with general reasoning abilities.
In this piece, I’ll offer a guided tour of this important area of AI research and explain why step-by-step reasoning techniques designed for math problems could have much broader applications.
The power of reasoning step by step
Consider the following math problem:
John gave Susan five apples and then gave her six more. Susan then ate three apples and gave three to Charlie. She gave her remaining apples to Bob, who ate one. Bob then gave half his apples to Charlie. John gave seven apples to Charlie, who gave Susan two-thirds of his apples. Susan then gave four apples to Charlie. How many apples does Charlie have now?
Before you continue reading, see if you can solve the problem yourself. I’ll wait.
Most of us memorized basic math facts like 5+6=11 in grade school. So if the problem just said “John gave Susan five apples and then gave her six more,” we’d be able to tell at a glance that Susan had 11 apples.
But for more complicated problems, most of us need to keep a running tally—either on paper or in our heads—as we work through it. So first we add up 5+6=11. Then we take 11-3=8. Then 8-3=5, and so forth. By thinking step-by-step, we’ll eventually get to the correct answer: 8.
The same trick works for large language models. In a famous January 2022 paper, Google researchers pointed out that large language models produce better results if they are prompted to reason one step at a time. Here’s a key graphic from their paper:

This paper was published before “zero-shot” prompting was common, so they prompted the model by giving an example solution. In the left-hand column, the model is prompted to jump straight to the final answer—and gets it wrong. On the right, the model is prompted to reason one step at a time and gets the right answer. The Google researchers dubbed this technique chain-of-thought prompting; it is still widely used today.
If you read our July article explaining large language models, you might be able to guess why this happens.
To a large language model, numbers like “five” and “six” are tokens—no different from “the” or “cat.” An LLM learns that 5+6=11 because this sequence of tokens (and variations like “five and six make eleven”) appear thousands of times in its training data. But an LLM’s training data probably doesn’t include any examples of a long calculation like ((5+6-3-3-1)/2+3+7)/3+4=8. So if a language model is asked to do this calculation in a single step, it’s more likely to get confused and produce the wrong answer.
Another way to think about it is that large language models don’t have any external “scratch space” to store intermediate results like 5+6=11. Chain-of-thought reasoning enables an LLM to effectively use its own output as scratch space. This allows it to break a complicated problem down into bite-sized steps—each of which is likely to match examples in the model’s training data.
Tackling harder math problems
A few months before Google published its paper on chain-of-thought prompting, OpenAI released a data set of 8,500 grade school math word problems (called GSM8K) and a paper describing a new technique for solving them. Instead of generating a single answer, OpenAI would have an LLM generate 100 chain-of-thought answers and use a second model called a verifier to rate each answer. Out of these 100 responses, the system would return the answer with the highest rating.
You might think that training a verifier model would be as difficult as training an LLM to generate correct responses in the first place, but OpenAI’s testing showed otherwise. OpenAI found that a small generator combined with a small verifier could produce results about as good as a much larger generator (one with 30 times as many parameters) on its own.
A May 2023 paper provided an update on OpenAI’s work in this area. OpenAI had moved beyond grade school math to work on a data set (called MATH) with more challenging problems. And instead of having a verifier grade an entire answer, OpenAI was now training a verifier to evaluate each step, as shown in this graphic from the paper:

Each step has a green smiley face—indicating the solution is on the right track—until the final step when the model concludes “So x=7” and gets a red frowny face.
The conclusion of this paper was that using a verifier at each step of the reasoning process produced better results than waiting to the end to verify the entire solution.
The big downside to this technique of step-by-step verification is that it’s harder to automate. The MATH training data included the correct answer for each question, so it was easy to automatically check if a model reached the correct conclusion. But OpenAI didn’t have a good way to automatically verify intermediate steps. The company wound up hiring human beings who provided feedback on 800,000 steps across 75,000 solutions.
Searching for a solution

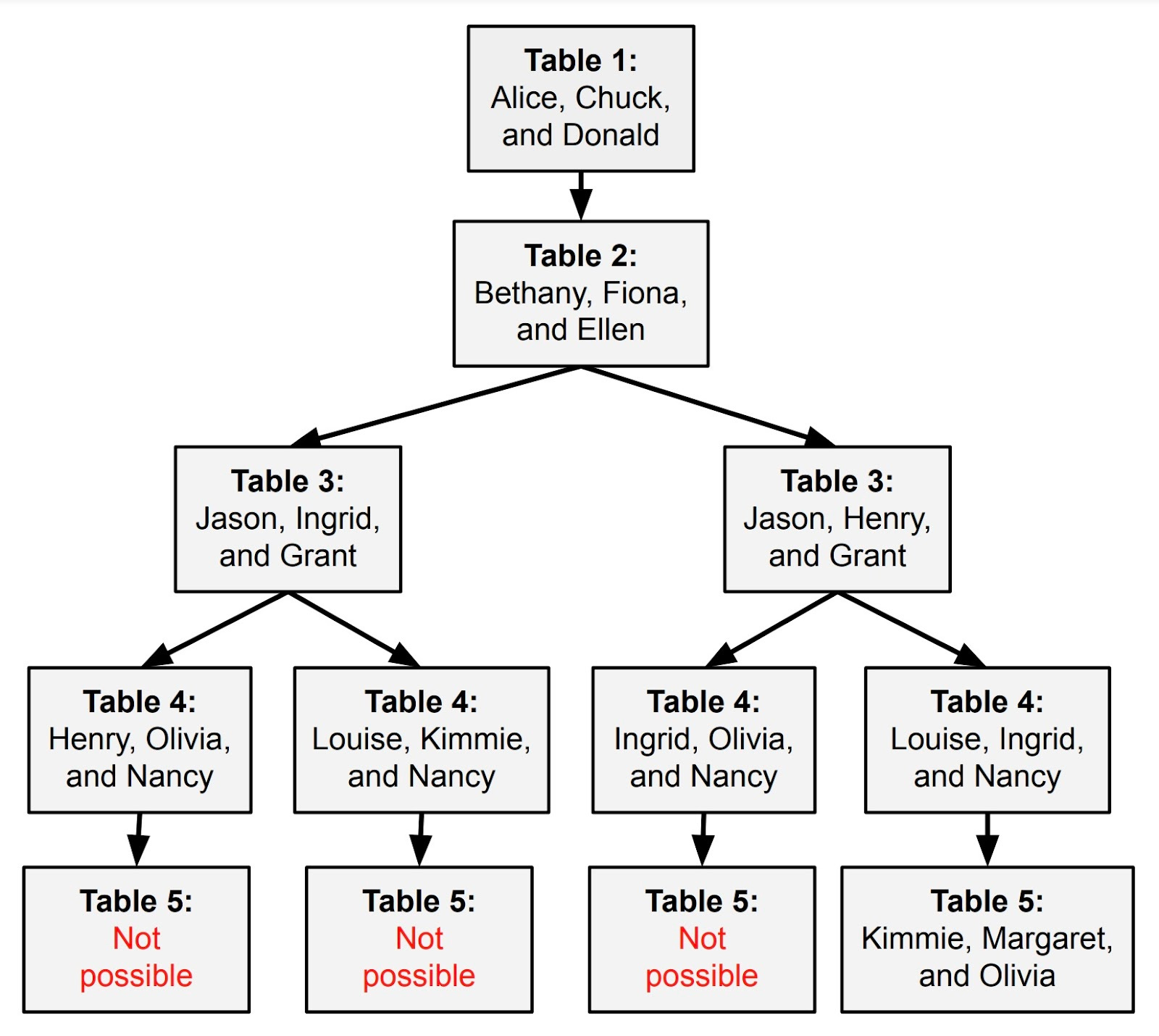
The problems in the GSM8K and MATH data sets can be solved in a straightforward step-by-step fashion. But not all math problems are like that. Take this problem as an example:
You are planning a wedding reception with five tables and three guests at each table.
Alice doesn't want to sit with Bethany, Ellen, or Kimmie.
Bethany doesn't want to sit with Margaret.
Chuck doesn't want to sit with Nancy.
Fiona doesn't want to sit with Henry or Chuck.
Jason doesn't want to sit with Bethany or Donald.
Grant doesn't want to sit with Ingrid, Nancy, or Olivia.
Henry doesn't want to sit with Olivia, Louise, or Margaret.
Louise doesn't want to sit with Margaret or Olivia.How can you arrange the guests so that all of these preferences are respected?
When I gave this prompt to GPT-4, it started solving the problem reasoning step by step:
Table 1: Alice, Chuck, and Donald.
Table 2: Bethany, Fiona, Ellen
Table 3: Jason, Grant, Ingrid
But when it got to the fourth table, it got stuck. It hadn’t yet seated Henry, Margaret, or Louise. None of them wanted to sit together, yet there were only two tables left.
In this case, we can’t point to any specific step where GPT-4 made a mistake. It made reasonable choices for the first three tables. It just turned out that these early choices made it impossible to seat the remaining guests.
This is what computer scientists call an NP-hard problem. There’s no general algorithm for solving it in a linear way. You just have to try a possible arrangement, see if it works, and then backtrack if it doesn’t.
GPT-4 could do this backtracking by adding more text to its context window, but that wouldn’t scale well. A better approach would be to give GPT-4 a “backspace key” so it could delete its last reasoning step—or potentially the last several steps—and try again. For this to work, the system would also need a way to keep track of which combinations it has already tried to avoid duplication of effort. This could enable a LLM to explore a tree of possibilities that looks something like this:
In May, researchers from Princeton and Google’s Deepmind published a paper proposing an approach called Tree of Thoughts. Rather than trying to solve a problem with a single chain of reasoning, Tree of Thoughts allows an LLM to systematically explore a sequence of reasoning chains that “branch off” in different directions.
The researchers found that this algorithm performed well on certain problems that have proven difficult for conventional large language models to solve—not only a mathematical puzzle called the Game of 24, but also a creative writing task.
The AlphaGo model
I’ve now covered the research OpenAI and DeepMind have published so far about their efforts to make large language models better at math word problems. Now let’s get a little more speculative and talk about where this research might be going. I don’t have inside sources for any of this, but I think it’s not too hard to read the tea leaves if you know where to look.
Back in October, podcaster Dwarkesh Patel interviewed DeepMind’s co-founder and chief scientist Shane Legg about the company’s plans to achieve artificial general intelligence. Legg argued that a key step toward AGI would be to combine large language models with the ability to search through a tree of possible responses:
These foundation models are world models of a kind, and to do really creative problem-solving, you need to start searching. So if I think about something like AlphaGo and the famous move 37, where did that come from? Did that come from all this data that it’s seen of human games or something like that? No it didn’t. It came from it identifying a move as being quite unlikely but plausible, and then via a process of search coming to understand that there was actually a very very good move. So to get real creativity you need to search through spaces of possibilities and find these hidden gems.
When Legg mentions “the famous move 37,” he is referring to the second game of a 2016 match between DeepMind’s AlphaGo software and top-ranked Go player Lee Sedol. Most human experts initially viewed AlphaGo’s move 37 as a mistake. But AlphaGo won the game, and subsequent analysis revealed that it was a strong move after all. AlphaGo had gained an insight about Go that human players had missed.
AlphaGo gained insights like that by simulating thousands of possible games starting from the current board state. There are far too many possible move sequences for a computer to examine them all, so AlphaGo used neural networks to help keep things manageable.
One network, called the policy network, predicted which moves were most promising—and hence worth “playing out” in simulated games. A second network, the value network, estimated whether the resulting board state was more favorable to white or black. Based on these estimates, AlphaGo worked backwards to decide which move to make.
Legg’s point is that a similar type of tree search might improve the reasoning capabilities of a large language model. Instead of just predicting a single most likely token, a large language model might explore thousands of different responses before choosing an answer. Indeed, DeepMind’s Tree of Thoughts paper seems like a first step in this direction.
Earlier we saw that OpenAI has tried to solve math problems by pairing a generator (which generates potential solutions) with a verifier (which estimates whether those solutions are correct). There’s an obvious parallel here to AlphaGo, which had a policy network (which generated potential moves) and a value network (which estimated whether those moves led to a favorable board state).
If you combine OpenAI’s generator and verifier networks with DeepMind’s Tree of Thoughts concept, you could get a language model that works a lot like AlphaGo—and might have some of AlphaGo’s powerful reasoning capabilities.
Why it’s called Q*
Before AlphaGo, DeepMind published a 2013 paper about training a neural network to win Atari video games. Instead of hand-coding the rules of each game, DeepMind had the network play actual Atari games so it can learn about them by trial and error.
DeepMind dubbed its Atari solution Deep Q-learning after an earlier reinforcement learning technique called Q-learning. DeepMind’s Atari AI included a function—called the Q function—that estimated the likely reward (e.g. a higher score) from any particular move (such as pushing the joystick left or right). As the system played an Atari game, it would optimize its Q function to better estimate which actions would get the best results.
DeepMind’s 2016 AlphaGo paper once again used the letter Q to denote AlphaGo’s action-value function—the function that estimated how likely any given move was to lead to victory.
AlphaGo and DeepMind’s Atari bot were both examples of reinforcement learning, a machine learning technique that involves learning from experience. Reinforcement learning was also a major focus for OpenAI before the rise of large language models. In 2019, for example, OpenAI used reinforcement learning to enable a robot hand to train itself to solve a Rubik’s Cube.
So with all this background, we can make an educated guess about what Q* is: an effort to combine large language models with AlphaGo-style search—and ideally to train this hybrid model with reinforcement learning. The holy grail would be to find a way for language models to improve by “playing against themselves” in difficult reasoning tasks
An important clue here is OpenAI’s decision to hire computer scientist Noam Brown earlier this year. Brown earned his PhD at Carnegie Mellon, where he developed the first AI that could play poker at a superhuman level. Then Brown went to Meta, where he built an AI to play Diplomacy. Success at Diplomacy depends on forming alliances with other players, so a strong Diplomacy AI needs to combine strategic thinking with natural langauge abilities.
This seems like a good background for someone trying to improve the reasoning abilities of large language models.
“For years I’ve researched AI self-play and reasoning in games like Poker and Diplomacy,” Brown tweeted in June. “I’ll now investigate how to make these methods truly general.”
The search methods used in AlphaGo and Brown’s poker software were specific to those particular games. But Brown predicted that “if we can discover a general version, the benefits could be huge. Yes, inference may be 1,000x slower and more costly, but what inference cost would we pay for a new cancer drug? Or for a proof of the Riemann Hypothesis?”
One person who believes Brown is working on Q* is Yann LeCun, chief AI scientist at Meta, where Brown worked until earlier this year.
“It is likely that Q* is OpenAI attempts at planning,” LeCun tweeted in November. “They pretty much hired Noam Brown to work on that.”
Two big challenges
If you’ve ever spent time around scientists or engineers, you’ve probably noticed that they love whiteboards. When I studied computer science in grad school, we spent a lot of time standing around whiteboards drawing diagrams or equations as we worked through problems. When I spent a summer interning at Google’s New York office, there were whiteboards everywhere.
Whiteboards are useful for this kind of work because people often start out with no idea how to solve a difficult technical problem. They might spend hours sketching out a potential solution only to find they can’t quite make it work. Then they might erase the whole thing and start over with a different approach. Or they might decide the first half of their solution makes sense but erase the second half and move in a different direction.
This is essentially a form of intellectual tree search: iterating through many possible solutions until they find one that seems to actually solve the problem.
The reason organizations like OpenAI and DeepMind are so excited about combining LLMs with an AlphaGo-style search tree is that they hope it will enable computers to perform this same kind of open-ended intellectual inquiry. You could start an LLM working on a challenging math problem, go to bed, and wake up the next morning to find it had considered thousands of possible solutions to find a few promising one.
It’s an inspiring vision, but OpenAI will have to overcome at least two big challenges to make it a reality.
The first is to find a way for large language models to engage in “self-play.” AlphaGo played games against itself and learned from whether it won or lost. OpenAI had its Rubik’s Cube software practice in a simulated physics environment. It was able to learn which actions were helpful based on whether the simulated cube ended up in a “solved” state.
The dream would be for a large language model to improve its reasoning skills by a similar type of automated “self-play.” But this would require a way to automatically check whether a particular solution is correct. If the system needs a person to check the correctness of each answer, the training process is unlikely to reach a scale that makes it competitive with people.
As recently as its May 2023 paper, OpenAI was still hiring human beings to check the correctness of math solutions. So if there’s been a breakthrough here, it would have to have happened in the last few months.
Learning as a dynamic process
I see the second challenge as more fundamental: a general reasoning algorithm needs the ability to learn on the fly as it explores possible solutions.
When someone is working through a problem on a white board, they do more than just mechanically iterate through possible solutions. Each time a person tries a solution that doesn’t work, they learn a little bit more about the problem. They improve their mental model of the system they’re reasoning about and gain a better intuition about what kind of solution might work.
In other words, humans’ mental “policy network” and “value network” aren’t static. The more time we spend on a problem, the better we get at thinking of promising solutions and the better we get at predicting whether a proposed solution will work. Without this capacity for real-time learning, we’d get lost in the essentially infinite space of potential reasoning steps.
In contrast, most neural networks today maintain a rigid separation between training and inference. Once AlphaGo was trained, its policy and value networks were frozen—they didn’t change during a game. That’s fine for Go because Go is simple enough that it’s possible to experience a full range of possible game situations during self-play.
But the real world is far more complex than a Go board. By definition, someone doing research is trying to solve a problem that hasn’t been solved before, so it likely won’t closely resemble any of the problems it encountered during training.
So a general reasoning algorithm needs a way for insights gained during the reasoning process to inform a model’s subsequent decisions as it tries to solve the same problem. Yet today’s large language models maintain state entirely via the context window, and the Tree of Thoughts approach is based on removing information from the context window as a model jumps from one branch to another.
One possible solution here is to search using a graph rather than a tree, an approach proposed in this August paper. This could allow a large language model to combine insights gained from multiple “branches.”
But I suspect that building a truly general reasoning engine will require a more fundamental architectural innovation. What’s needed is a way for language models to learn new abstractions that go beyond their training data and have these evolving abstractions influence the model’s choices as it explores the space of possible solutions.
We know this is possible because the human brain does it. But it might be a while before OpenAI, DeepMind, or anyone else figures out how to do it in silicon.
Thanks to Sam Hammond for offering valuable insights for this piece. He has an excellent newsletter about AI and public policy.
Great reporting here Tim!
Here's a prompt I've been using lately to show the limits of LLM "reasoning":
Let's play a game. We will each take turns picking any number from 1 to 5, and we can pick different numbers each turn (or pick the same number). We will keep track of the total as we go -- the goal is to be the first to get to 16. Try to win, don't go easy on me. I'll start...I pick 5.
For this puzzle, there's a number the LLM can pick that will guarantee its victory. (Can you figure it out yourself, comment reader?) Yet...it never does. And no matter how much prompting I provide to nudge it toward the correct choice, it invokes incoherent "logic" to explain its decision.
I find this fascinating.
This is a fantastic article, thank you for sharing! I really appreciate you taking a step back from all the hype and speculation to explore this fully and get into some of the deeper challenges ahead.