
Anthropic and Google's new mid-sized models are on par with GPT-4o
Leading labs have been delivering big price cuts—but only small performance gains.

Yesterday Anthropic announced Claude 3.5 Sonnet, a new version of its mid-range language model. It also published a chart that strikingly illustrates the company’s strategy:
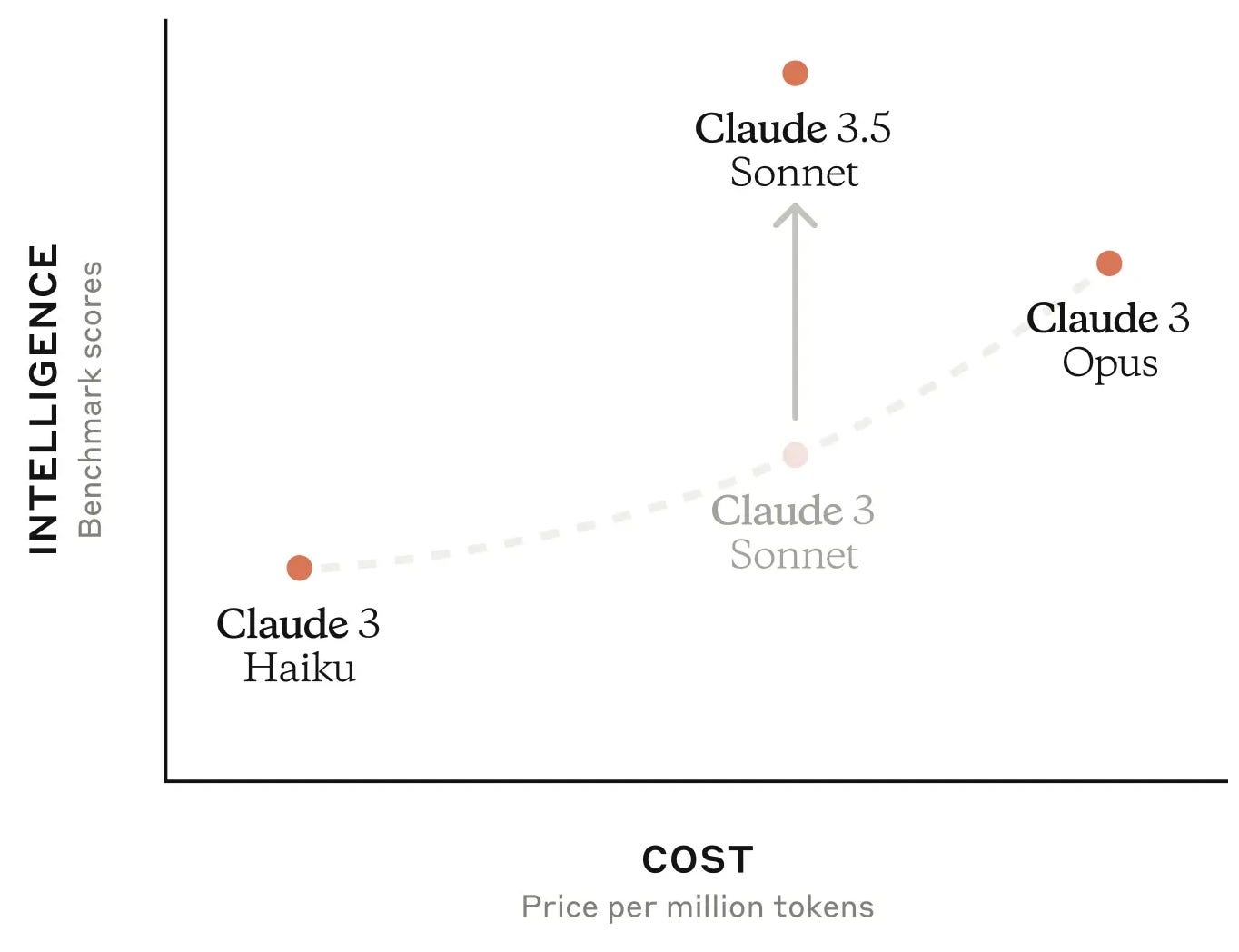
When Anthropic released Claude 3 in March, it came in three sizes:
Opus had the best reasoning capabilities (MMLU score of 86.8 percent), but cost $15 per million input tokens.
Sonnet was less powerful than Opus (MMLU score of 79.0 percent) but cost $3 per million input tokens.
Haiku was the least powerful model (MMLU score of 75.2 percent) but only cost $0.25 per million input tokens.
Claude 3.5 Sonnet still costs $3 per million output tokens, but benchmarks show it outperforming Claude 3 Opus with an MMLU score of 88.7 percent. Given this impressive performance, it’s hard to see why anyone would pay five times as much to use Claude 3 Opus.
Anthropic is following in Google’s footsteps here. Back in December, Google announced that Gemini 1.0 would come in three sizes: Ultra, Pro, and Nano. While Google released benchmarks for the high-end Ultra model in December, it didn’t actually become available until February.
Then just a week after Ultra’s release, Google announced Gemini 1.5 Pro. Google claimed that it achieved “comparable quality to 1.0 Ultra, while using less compute.” And crucially, “less compute” meant Google could afford to price 1.5 Pro aggressively. It costs $3.50 per million input tokens for prompts up to 128,000 tokens.
Like Anthropic, Google appears to be shelving its previous high-end model. Today Gemini 1.0 Ultra isn’t even listed on Google’s API pricing page.
OpenAI hasn’t quite adopted the three-tier pricing model of its rivals, but I see last month’s announcement of GPT-4o in a similar light. OpenAI’s announcement event focused on GPT-4o’s capacity for real-time understanding of audio and video. But OpenAI also said the model was twice as fast and half the price of GPT-4 Turbo—which itself was two to three times cheaper than the original GPT-4. OpenAI downplayed traditional benchmarks like MMLU, merely stating “GPT-4o achieves GPT-4 Turbo-level performance on text, reasoning, and coding intelligence.”
In short, in recent months all three companies have delivered aggressive price cuts but only modest performance gains.
With that said, there have been performance gains. I’ve spent the last 24 hours testing the three leading LLMs—Claude 3.5 Sonnet, Gemini 1.5 Pro, and GPT-4o—on a series of hand-crafted challenges.
My testing shows that all three models are more capable than previous top-of-the-line foundation models and their capabilities are very similar to one another. Read on for details about my testing, and then some thoughts about the broader implications.
Keep reading with a 7-day free trial
Subscribe to Understanding AI to keep reading this post and get 7 days of free access to the full post archives.