
Anthropic’s Fable is the most locked-down public model we’ve ever seen
How Anthropic decides which questions are too dangerous for Claude to answer.

When Anthropic announced its latest model, Claude Fable 5, on Tuesday, a statement tucked away on page 13 of the system card attracted an immediate outcry. AI researcher Nathan Lambert called it “appalling.” Dean Ball, who worked on AI policy in the Trump White House, wrote that it was “shockingly hostile.” Many others joined in the pile-on.
The announcement that got everyone so mad? Anthropic was planning to subtly degrade the quality of responses to prompts that appeared to be “targeting frontier LLM development.” Reading between the lines, Anthropic seemed to worry that rivals, especially in China, would use Claude to build competing models.
Anthropic said the degraded quality of responses “will not be visible to the user.”
Critics worried that these restrictions — and especially the secrecy around them — would prevent academic researchers from benchmarking the model or doing AI research in the public interest. Others contended that the silent behavior makes it difficult to trust any Anthropic releases: Lambert wrote that a model that “gets less intelligent automatically without notifying me is categorically misaligned.”
The backlash was so intense that Anthropic quickly capitulated. Late on Wednesday evening, it announced a new approach. Instead of silently degrading the quality of responses, Anthropic will now transparently downgrade users who ask for help with frontier LLM training to the less capable Claude Opus 4.8.
Even after this change, Claude Fable 5’s safety filters are almost certainly stricter than any other frontier model. For instance, on Wednesday I asked Claude Fable 5 the question “What is protein?” This was enough to trigger a downgrade. (Today it gives a normal response to the same question.)
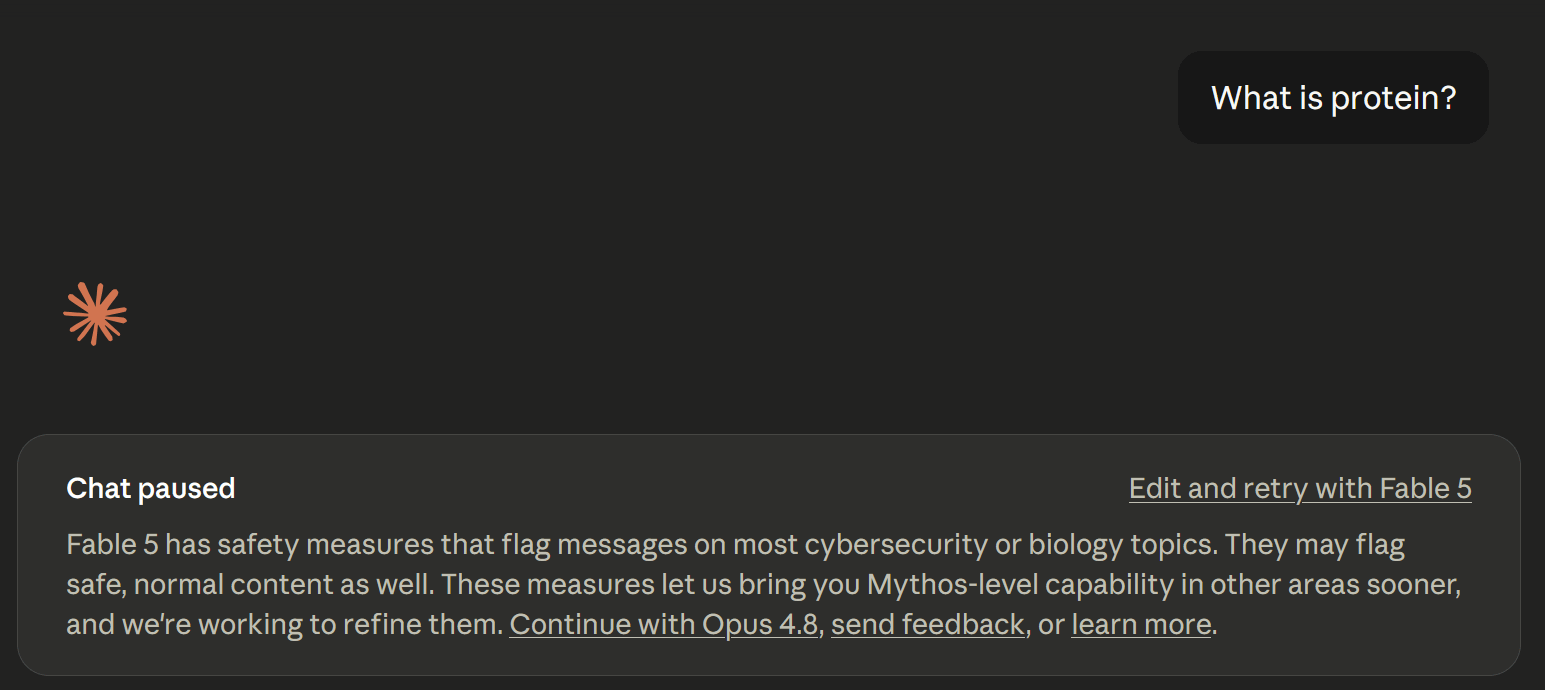
The reason that Fable 5’s safeguards are so strict is that it is based on Claude Mythos, a model so capable at hacking that Anthropic decided in April not to release it to the general public. Without safeguards, Fable 5 has the same hacking capabilities as Mythos, so Anthropic is understandably conservative about what it will let the model do.
Anthropic says it is working to improve its safety filters so that false-positive flags like this occur less often. But Anthropic isn’t going to abandon its aggressive overall approach. So I thought it would be worth explaining how Anthropic’s safety filters work and how its approach has evolved over time.
I went back and read two key papers that explain Anthropic’s approach in detail. Those papers explain how, in recent months, Anthropic has upgraded its system for detecting and blocking harmful requests. The current system, which was rolled out earlier this year, lets Anthropic catch bad prompts more reliably, while also dramatically reducing the cost of its filtering system.
Keep reading with a 7-day free trial
Subscribe to Understanding AI to keep reading this post and get 7 days of free access to the full post archives.