
Grandes modelos de linguagem, explicados com o mínimo de matemática e jargão
Quer realmente entender como funcionam os grandes modelos de linguagem? Aqui está uma introdução gentil.


We are thrilled to publish this Portuguese translation of our explainer on large language models translated by Carlos Dutra. The article is also available in Spanish.
Artigo original escrito por Timothy B. Lee e Sean Trott.
Tradução de Carlos Dutra.
A tradução deste artigo busca tornar mais acessível a participação do público lusófono nas conversas que estão ocorrendo em torno da Inteligência Artificial e dos grandes modelos de linguagem (LLM).
Em geral, busquei manter um equilíbrio entre a precisão técnica e a facilidade de compreensão para o leitor, reconhecendo que no campo da Inteligência Artificial ainda não há um consenso geral sobre a tradução de muitos conceitos. Da mesma forma, busquei respeitar o trabalho dos autores e pesquisadores, preservando o máximo possível a integridade do artigo original e dos estudos ali referidos, sem perder de vista a necessidade de fornecer clareza e contexto suficientes para o leitor lusófono.
Durante o processo de tradução, me deparei com certas problemáticas. Por exemplo, você encontrará alguns conceitos que não foram traduzidos ou que foram traduzidos parcialmente, assim como palavras ou frases completas para as quais optei por incluir a tradução acompanhada da versão original em inglês, principalmente nos casos de conceitos técnicos chave e frases que foram objeto de estudo das pesquisas citadas.
Além disso, o artigo em inglês faz referência a certos jogos de palavras que, ao serem traduzidos, perdiam o sentido ou a ambiguidade que os autores desejavam aproveitar para explicar seu argumento. Por isso, nestes casos, substitui os originais por alternativas que mantivessem sua intenção e efeito desejado.
Por fim, é importante considerar que os temas abordados no artigo são parte de uma conversa em constante evolução. Portanto, recomendamos consultar as fontes originais e realizar uma pesquisa própria com as ferramentas fornecidas.
Obrigado a Gabriel Adriano de Melo por revisar esta tradução.
Se você tem interesse em ler mais artigos como este, recomendo que se inscreva aqui no 'Understanding AI', a newsletter de Timothy B. Lee, bem como 'The Counterfactual', a newsletter de Sean Trott.
Quando o ChatGPT foi introduzido no final de 2022, causou um grande impacto na indústria tecnológica e no mundo em geral. Os pesquisadores de aprendizado de máquina, ou machine learning em inglês, vinham experimentando com grandes modelos de linguagem, ou Large Language Models (LLMs) em inglês, há alguns anos até aquele momento, mas o público em geral não estava prestando muita atenção e não percebia o quão poderosos eles haviam se tornado.
Hoje em dia, quase todo mundo já ouviu falar dos LLMs, e dezenas de milhões de pessoas já testaram. No entanto, ainda são poucas as pessoas que entendem como funcionam.
Se você sabe alguma coisa sobre esse assunto, provavelmente já ouviu falar que os LLMs são treinados para "prever a próxima palavra" e que requerem grandes quantidades de texto para fazer isso. Mas é aí que a explicação costuma parar. Os detalhes de como eles preveem a próxima palavra são frequentemente tratados como um profundo mistério.
Uma razão para isso é a forma incomum como esses sistemas foram desenvolvidos. O software convencional é criado por programadores humanos que fornecem aos computadores instruções explícitas e passo a passo. Em contraste, o ChatGPT é construído sobre uma rede neural que foi treinada utilizando bilhões de palavras de linguagem comum.
Como resultado, ninguém na Terra compreende completamente o funcionamento interno dos LLMs. Os pesquisadores estão trabalhando para obter uma melhor compreensão, mas este é um processo lento que levará anos - talvez décadas - para ser concluído.
Ainda assim, há muito que os especialistas entendem sobre como esses sistemas funcionam. O objetivo deste artigo é tornar grande parte desse conhecimento acessível a um público amplo. Vamos tentar explicar o que se sabe sobre o funcionamento interno desses modelos sem recorrer a jargões técnicos ou matemática avançada.
Começaremos explicando os vetores de palavras, a forma surpreendente como os modelos de linguagem representam e raciocinam sobre a linguagem. Em seguida, mergulharemos profundamente no transformer, o componente básico para sistemas como o ChatGPT. Por fim, explicaremos como esses modelos são treinados e exploraremos por que um bom desempenho requer quantidades extraordinariamente grandes de dados.
Palavras representadas por vetores
Para entender como os modelos de linguagem funcionam, primeiro é necessário compreender como eles representam as palavras. Os seres humanos representam palavras com uma sequência de letras, como C-A-T para cat [gato]. Modelos de linguagem utilizam uma longa lista de números chamada vetor. Por exemplo, aqui está uma maneira de representar a palavra cat como um vetor:
[0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, …, 0.0002]
(O vetor completo possui 300 números - para ver todos, clique aqui e depois em “show the raw vector”).
Por que usar uma notação tão elaborada? Aqui está uma analogia. Washington DC está localizada a 38.9 graus de latitude Norte e 77 graus de longitude Oeste. Podemos representar isso usando uma notação de vetor:
Washington DC está em [38.9, 77]
Nova York está em [40.7, 74]
Londres está em [51.5, 0.1]
Paris está em [48.9, -2.4]
Esta notação é útil para raciocinar sobre relações espaciais entre cidades. Por exemplo, podemos notar que Nova York está próxima de Washington DC porque 38.9 está próximo de 40.7 e 77 está próximo de 74. Da mesma forma, Paris está próxima de Londres. No entanto, Paris está longe de Washington DC.
Os modelos de linguagem seguem uma abordagem semelhante: cada vetor1 representa um ponto em um "espaço de palavras" imaginário, onde palavras com significados mais semelhantes são posicionadas mais próximas umas das outras. Por exemplo, as palavras mais próximas de "cat" no espaço vetorial incluem “dog” [cachorro], “kitten” [gatinho] e “pet” [animal de estimação]. Uma das principais vantagens de representar palavras com vetores de números reais (em vez de uma sequência de letras, como “C-A-T”) é que os números permitem operações que as letras não permitem.
Como as palavras são muito complexas para serem representadas em apenas duas dimensões, os modelos de linguagem utilizam espaços vetoriais com centenas ou até milhares de dimensões. Embora a mente humana não consiga visualizar um espaço com tantas dimensões, os computadores são perfeitamente capazes de raciocinar sobre eles e produzir resultados úteis.
Os pesquisadores têm explorado vetores de palavras há décadas, mas o conceito realmente decolou quando o Google anunciou seu projeto word2vec em 2013. O Google analisou milhões de documentos coletados do Google News para descobrir quais palavras tendem a aparecer em frases semelhantes. Com o tempo, uma rede neural treinada para prever quais palavras tendem a aparecer em conjunto com outras aprendeu a posicionar palavras semelhantes, como "dog" e "cat", próximas umas das outras no espaço vetorial.
Os vetores de palavras do Google tinham outra propriedade intrigante: eles permitiam "raciocinar" sobre palavras usando aritmética vetorial. Por exemplo, os pesquisadores do Google pegaram o vetor para biggest ["o maior de todos"], subtraíram big [grande] e adicionaram small [pequeno]. A palavra mais próxima ao vetor resultante foi smallest [“o menor de todos”].
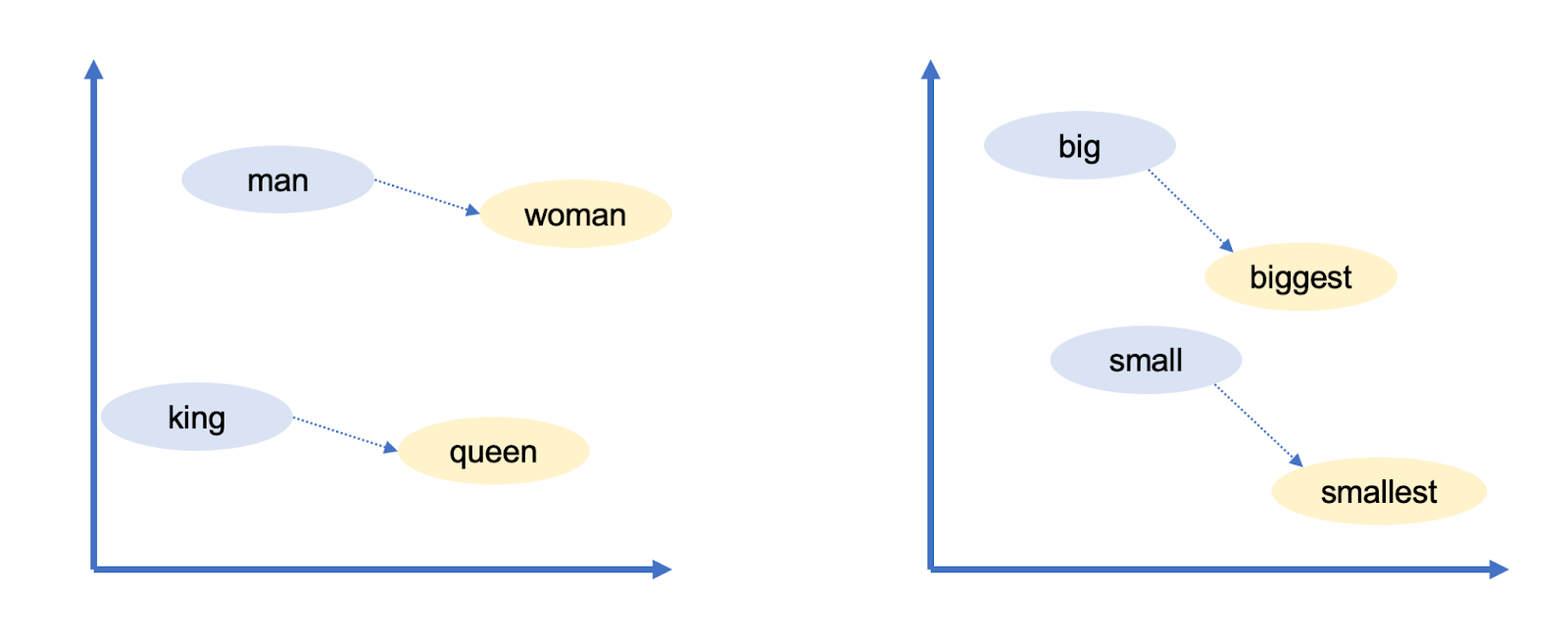
Você pode usar aritmética vetorial para fazer analogias! Neste caso, big é para biggest como small é para smallest. Os vetores de palavras do Google capturaram muitas outras relações:
Suíço está para Suíça como cambojano está para Camboja (nacionalidades)
Paris está para França como Berlim está para Alemanha (capitais)
Antiético está para ético como possível está para impossível (opostos)
Rato está para ratos como dólar está para dólares (plural)
Homem está para mulher como rei está para rainha (gênero)
Como esses vetores são construídos a partir da maneira como os humanos usam palavras, eles acabam refletindo muitos dos vieses presentes na linguagem humana. Por exemplo, em alguns modelos de vetor de palavras, médico menos homem mais mulher resulta em enfermeira. Mitigar vieses como este é um campo de pesquisa em constante evolução.
No entanto, os vetores de palavras são um bloco de construção útil para os modelos de linguagem porque codificam informações sutis, mas importantes, sobre as relações entre as palavras. Se um modelo de linguagem aprende algo específico sobre um gato (por exemplo: que às vezes vai ao veterinário), é provável que a mesma informação seja verdadeira para um gatinho ou um cachorro. Se um modelo aprende algo sobre a relação entre Paris e França (por exemplo, que compartilham um idioma), há uma boa chance de que o mesmo seja verdadeiro para Berlim e Alemanha, e para Roma e Itália.
O significado das palavras depende do contexto
Um esquema de vetor de palavras simples como este não captura um fato importante sobre a linguagem natural: palavras frequentemente têm múltiplos significados.
Por exemplo, a palavra banco pode se referir a uma instituição financeira ou a um assento longo. Ou considere as seguintes frases:
João pega uma revista
Suzana trabalha para uma revista
Os significados de "revista" nessas frases estão relacionados, mas são sutilmente diferentes. João pega uma revista física, enquanto Suzana trabalha para uma organização que publica revistas físicas.
Quando uma palavra tem dois significados não relacionados, como banco, os linguistas chamam isso de homônimos. Quando uma palavra tem dois significados intimamente relacionados, como acontece com revista, os linguistas chamam isso de polissemia.
Os LLMs como o ChatGPT são capazes de representar a mesma palavra com diferentes vetores, dependendo do contexto em que a palavra aparece. Há um vetor para banco (instituição financeira) e um diferente para banco (assento). Há um vetor para revista (publicação física) e outro para revista (organização). Como era de se esperar, os LLMs usam vetores mais similares para significados polissêmicos do que para significados homônimos.
Até agora, não mencionamos como os modelos de linguagem fazem isso - vamos abordar isso em breve. Mas estamos detalhando essas representações vetoriais porque são fundamentais para entender como os modelos de linguagem funcionam.
O software tradicional é projetado para operar com dados inequívocos. Se você pedir a um computador para calcular "2 + 3", não há ambiguidade sobre o que significam 2, +, ou 3. No entanto, a linguagem natural está repleta de ambiguidades que vão além de homônimos e polissemia:
Em "o cliente pediu ao mecânico para consertar seu carro", a quem seu se refere: ao cliente ou ao mecânico?
Em "a professora instou a aluna a fazer sua lição de casa", a quem sua se refere: à professora ou à aluna?
Em "Árvore ameaça cair em praça do Jardim Independência", a árvore está fazendo uma ameaça? Ou o risco de ela cair é grande?
As pessoas resolvem ambiguidades como essas com base no contexto, mas não existem regras simples ou determinísticas para fazer isso. Em vez disso, requer entender fatos sobre o mundo. Você precisa saber que os mecânicos geralmente consertam os carros de seus clientes, que os alunos geralmente fazem sua própria lição de casa e que as árvores, até onde sabemos, não ameaçam ninguém.
Os vetores fornecem uma maneira flexível para que os modelos de linguagem representem o significado preciso de cada palavra no contexto de uma frase específica. Agora vamos ver como eles fazem isso.
Transformando vetores de palavras em predições
GPT-3, o modelo por trás da versão original do ChatGPT2, é organizado em dezenas de camadas. Cada camada recebe uma sequência de vetores como entradas — um vetor para cada palavra no texto de entrada — e adiciona informações para ajudar a esclarecer o significado dessa palavra e prever melhor qual palavra pode vir a seguir.
Vamos começar olhando um exemplo estilizado:
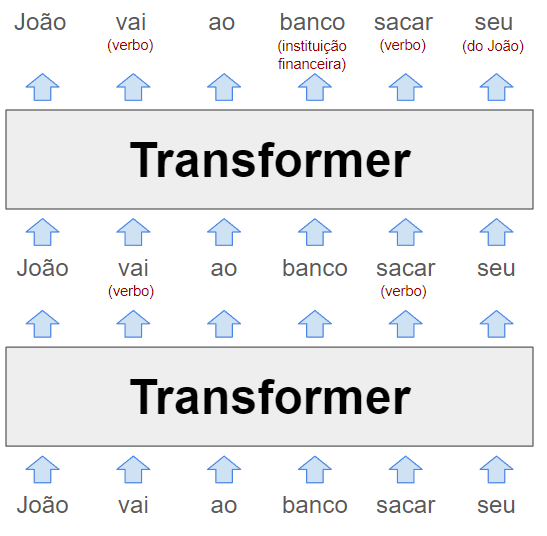
Cada camada de um LLM é um transformer, uma arquitetura de rede neural que foi introduzida pela primeira vez pelo Google em um artigo icônico de 2017.
A entrada do modelo, mostrada na parte inferior do diagrama, é a frase parcial "João vai ao banco sacar seu". Essas palavras, representadas como vetores word2vec, são inseridas no primeiro transformer.
O transformer descobre que vai e sacar são ambos verbos. Representamos esse contexto adicionado como um texto em vermelho entre parênteses, mas na realidade o modelo representaria essas informações dentro dos próprios vetores de palavras, difíceis de interpretar para os humanos. Esses novos vetores, conhecidos como estados ocultos (hidden state), são passados para o próximo transformer na sequência.
O segundo transformer adiciona mais outras partes de contexto: ele esclarece que banco se refere a uma instituição financeira em vez de um assento, e que seu é um pronome que se refere a João. O segundo transformer produz outro conjunto de vetores de estado oculto que reflete tudo o que o modelo aprendeu até aquele ponto.
O diagrama acima retrata um LLM puramente hipotético, então não leve os detalhes muito a sério. Em breve daremos uma olhada na pesquisa sobre modelos de linguagem reais. LLMs reais tendem a ter muito mais do que duas camadas. A versão mais poderosa do GPT-3, por exemplo, possui 96 camadas.
Pesquisas sugerem que as primeiras camadas se concentram em entender a sintaxe da frase e resolver ambiguidades como mostramos acima. Camadas posteriores (que não estamos mostrando para manter o diagrama em um tamanho viável) trabalham para desenvolver uma compreensão de alto nível do texto como um todo.
Por exemplo, enquanto um LLM "lê" um conto, parece manter um registro de uma variedade de informações sobre os personagens do conto: gênero e idade, relacionamentos com outros personagens, localização passada e atual, personalidades e objetivos, e assim por diante.
Os pesquisadores não entendem exatamente como os LLMs mantêm o controle dessas informações, mas, logicamente falando, o modelo deve estar fazendo isso modificando os vetores ocultos à medida que são passados de uma camada para a próxima, então é útil que nos LLMs modernos esses vetores sejam extremamente grandes
Por exemplo, a versão mais poderosa do GPT-3 usa vetores de palavras com 12.288 dimensões. Isso significa que cada palavra é representada por uma lista de 12.288 números. Isso é 20 vezes maior do que o esquema word2vec do Google de 2013. Você pode pensar em todas essas dimensões extras como uma espécie de "espaço de rascunho" que o GPT-3 pode usar para fazer anotações sobre o contexto de cada palavra. As anotações feitas por camadas anteriores podem ser lidas e modificadas por camadas posteriores, permitindo que o modelo aprimore gradualmente sua compreensão do texto como um todo.
Então, suponha que mudamos nosso diagrama acima para representar um modelo de linguagem de 96 camadas interpretando uma história de 1.000 palavras. A 60ª camada poderia incluir um vetor para João com um comentário como "(personagem principal, masculino, casado com Cheryl, primo de Donald, de Minnesota, atualmente em Boise, tentando encontrar sua carteira perdida)". Novamente, todos esses fatos (e provavelmente muito mais) seriam de alguma forma codificados em uma lista de 12.288 números correspondentes à palavra João. Ou talvez parte dessas informações possa ser codificada nos vetores de 12.288 dimensões correspondentes a Cheryl, Donald, Boise, carteira ou outras palavras na história.
O objetivo é que a 96ª e última camada da rede produza um estado oculto para a palavra final que inclua todas as informações necessárias para prever a próxima palavra.
Posso ter sua atenção, por favor?
Agora vamos falar sobre o que acontece dentro de cada transformer. O transformer tem um processo de dois passos para atualizar o estado oculto de cada palavra do texto de entrada:
No passo de atenção (attention step), as palavras "buscam" por outras palavras que têm contexto relevante e compartilham informações entre si
No passo de propagação direta (feed-forward step), cada palavra "pensa sobre" as informações reunidas em passos de atenção anteriores e tenta prever a próxima palavra
É claro que é a rede e não as palavras individuais que realizam esses passos. Mas estamos formulando as coisas desta maneira para enfatizar que os transformers tratam as palavras, em vez de frases ou passagens inteiras, como a unidade básica de análise. Essa abordagem permite que os LLMs aproveitem ao máximo o imenso poder de processamento paralelo dos chips de GPU (graphics processing unit) modernos. E também ajuda os LLMs a escalarem para textos com milhares de palavras. Essas são duas áreas em que modelos de linguagem anteriores tiveram dificuldades.
Você pode pensar no mecanismo de atenção como um serviço de pareamento, ou combinação, de palavras. Cada palavra faz uma lista (chamada vetor de consulta) descrevendo as características das palavras que está procurando. Cada palavra também faz uma lista (chamada vetor chave) descrevendo suas próprias características. A rede compara cada vetor chave com cada vetor de consulta (calculando um produto escalar) para encontrar as palavras que são a melhor combinação. Uma vez que encontra uma combinação, transfere informações da palavra que produziu o vetor chave para a palavra que produziu o vetor de consulta.
Por exemplo, na seção anterior, mostramos um transformer hipotético descobrindo que, na frase parcial "João vai ao banco sacar seu", seu se refere a João. Aqui está como isso poderia ser visto nos bastidores. O vetor de consulta para seu poderia efetivamente dizer "Estou procurando: um substantivo que descreva uma pessoa do sexo masculino". O vetor chave para João poderia dizer "Eu sou: um substantivo que descreve uma pessoa do sexo masculino". A rede detectaria que esses dois vetores correspondem e transferiria informações sobre o vetor para João para o vetor para seu.
Cada camada de atenção tem várias "cabeças de atenção" (attention heads), o que significa que esse processo de troca de informações acontece várias vezes (em paralelo) em cada camada. Cada cabeça de atenção se concentra em uma tarefa diferente:
Uma cabeça de atenção pode combinar pronomes com substantivos, como discutimos acima
Outra pode trabalhar na resolução do significado de homônimos como banco
Uma terceira pode vincular frases compostas por duas palavras, como "Joe Biden"
E assim por diante.
As cabeças de atenção frequentemente operam em sequência, com os resultados de uma operação de atenção em uma camada se tornando uma entrada para uma cabeça de atenção em uma camada subsequente. De fato, cada uma das tarefas que acabamos de listar poderia facilmente exigir várias cabeças de atenção em vez de apenas uma.
A maior versão do GPT-3 tem 96 camadas com 96 cabeças de atenção cada, então o GPT-3 realiza 9.216 operações de atenção cada vez que prevê uma nova palavra.
Um exemplo do mundo real
Nas últimas duas seções, apresentamos uma versão estilizada de como as cabeças de atenção funcionam. Agora, vamos ver pesquisas sobre o funcionamento interno de um modelo de linguagem real. No ano passado, cientistas da Redwood Research estudaram como o GPT-2, um predecessor do ChatGPT, previu a próxima palavra para o texto em inglês "When Mary and John went to the store, John gave a drink to", que em português podemos traduzir para “Quando Mary e John foram a loja, John deu uma bebida para”. Para fins práticos, analisaremos o texto utilizando a versão traduzida para o português.
O GPT-2 previu que a próxima palavra seria Mary. Os pesquisadores descobriram que três tipos de cabeças de atenção contribuíram para essa previsão:
Três cabeças que chamaram de Cabeças de Movimento de Nome (Name Mover Heads) copiaram informações do vetor de Mary para o vetor de entrada final (correspondente a palavra para). O GPT-2 usa as informações nesse vetor mais à direita para prever a próxima palavra
Como a rede decidiu que Mary era a palavra certa para copiar? Retrocedendo pelo processo computacional do GPT-2, os cientistas encontraram um grupo de quatro cabeças de atenção que chamaram de Cabeças de Inibição de Sujeito (Subject Inhibition Heads) que marcaram o segundo vetor de John de uma maneira que bloqueou as Cabeças de Movimento de Nome de copiar o nome John
Como as Cabeças de Inibição de Sujeito sabiam que John não deveria ser copiado? Retrocedendo ainda mais, a equipe encontrou duas cabeças de atenção que chamaram de Cabeças de Token Duplicado (Duplicate Token Heads). Eles marcaram o segundo vetor de John como um duplicado do primeiro vetor de John, o que ajudou as Cabeças de Inibição de Sujeito a decidir que John não deveria ser copiado
Em resumo, essas nove cabeças de atenção permitiram ao GPT-2 entender que "John deu uma bebida para John" não faz sentido e escolher "John deu uma bebida para Mary" em vez disso.
Adoramos esse exemplo porque ilustra o quão difícil será entender completamente os LLMs. A equipe de cinco membros da Redwood publicou um artigo de 25 páginas explicando como identificaram e validaram essas cabeças de atenção. No entanto, mesmo depois de todo esse trabalho, ainda estamos longe de ter uma explicação abrangente do motivo pelo qual o GPT-2 decidiu prever Mary como a próxima palavra.
Por exemplo, como o modelo sabia que a próxima palavra deveria ser o nome de alguém e não outro tipo de palavra? É fácil pensar em frases semelhantes em que Mary não seria uma boa previsão para a próxima palavra. Por exemplo, na frase "quando Mary e John foram ao restaurante, John deu suas chaves", as próximas palavras lógicas seriam "ao manobrista".
Presumivelmente, com pesquisa suficiente, os cientistas da computação poderiam descobrir e explicar etapas adicionais no processo de raciocínio do GPT-2. Eventualmente, eles podem ser capazes de desenvolver uma compreensão abrangente de como o GPT-2 decidiu que Mary é a palavra mais provável para essa frase. Mas poderia levar meses ou até anos de esforço adicional apenas para entender a previsão de uma única palavra.
Os modelos de linguagem subjacentes ao ChatGPT - GPT-3 e GPT-4 - são significativamente maiores e mais complexos que o GPT-2. Eles são capazes de raciocínio mais complexo do que a simples tarefa de completar frases estudada pela equipe da Redwood. Portanto, explicar completamente como esses sistemas funcionam será um projeto enorme que a humanidade provavelmente não concluirá tão cedo.
O passo de propagação direta
Depois que as cabeças de atenção transferem informações entre os vetores de palavras, há uma rede feed-forward3 que “pensa” sobre cada vetor de palavra e tenta prever a próxima palavra. Nesta etapa, não há troca de informações entre palavras: a camada feed-forward analisa cada palavra isoladamente. No entanto, a camada feed-forward tem acesso a qualquer informação que tenha sido previamente copiada por uma cabeça de atenção. Esta é a estrutura da camada feed-forward na maior versão do GPT-3:
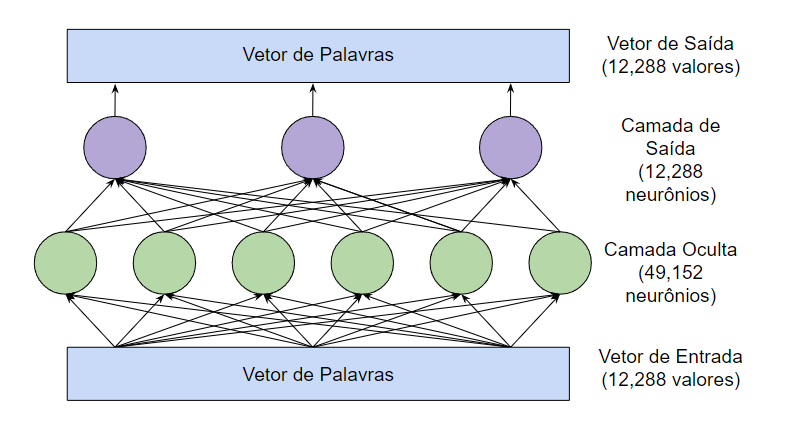
Os círculos verde e roxo são neurônios: funções matemáticas que calculam uma soma ponderada de suas entradas.4
O que torna a camada feed-forward poderosa é o seu enorme número de conexões. Desenhamos esta rede com três neurônios na camada de saída e seis neurônios na camada oculta, mas as camadas feed-forward do GPT-3 são muito maiores: 12.288 neurônios na camada de saída (correspondendo aos vetores de palavra de 12.288 dimensões do modelo) e 49.152 neurônios na camada oculta.
Portanto, na maior versão do GPT-3, há 49.152 neurônios na camada oculta com 12.288 entradas (e, portanto, 12.288 parâmetros) para cada neurônio. E há 12.288 neurônios de saída com 49.152 valores de entrada (e, portanto, 49.152 parâmetros) para cada neurônio. Isso significa que cada camada feed-forward tem 49.152 * 12.288 + 12.288 * 49.152 = 1,2 bilhões de parâmetros. E há 96 camadas feed-forward, totalizando 1,2 bilhões * 96 = 116 bilhões de parâmetros! Isso representa quase dois terços do total geral de 175 bilhões de parâmetros do GPT-3.
Em um artigo de 2020, pesquisadores da Universidade de Tel Aviv descobriram que as camadas feed-forward funcionam por meio de correspondência de padrões: cada neurônio na camada oculta corresponde a um padrão específico no texto de entrada. Aqui estão alguns dos padrões que foram correspondidos por neurônios em uma versão de 16 camadas do GPT-2:
Um neurônio na camada 1 correspondia a sequências de palavras terminando com a palavra "substitutos".
Na camada 6, uma neurônio correspondeu a sequências relacionadas ao militarismo, ou "the military" em inglês, com finais como "base" ou "bases", uma vez que, em inglês, "base militar" é expressa, estritamente, como "military base".
Um neurônio na camada 13 correspondia a sequências terminando com um intervalo de tempo, como "entre 3 pm e 7" ou "das 7:00 pm de sexta-feira até".
Um neurônio na camada 16 correspondia a sequências relacionadas a programas de televisão, como "a versão diurna original da NBC, arquivada" ou "a exibição em horário diferente adicionou 57 por cento de audiência ao episódio".
Como pode ver, os padrões se tornaram mais abstratos nas camadas posteriores. As camadas iniciais tendiam a corresponder a palavras específicas, enquanto as camadas posteriores correspondiam a frases que se encaixavam em categorias semânticas mais amplas, como programas de televisão ou intervalos de tempo.
Isso é interessante porque, como mencionado anteriormente, a camada feed-forward examina apenas uma palavra por vez. Portanto, quando classifica a sequência "a versão diurna original da NBC, arquivada" como relacionada à televisão, ela só tem acesso ao vetor para arquivada, não a palavras como NBC ou diurna.
Presumivelmente, a camada feed-forward pode perceber que arquivada faz parte de uma sequência relacionada à televisão porque as cabeças de atenção anteriormente moveram informações contextuais para o vetor arquivada.
Quando um neurônio corresponde a um desses padrões, ele adiciona informações ao vetor de palavra. Embora essas informações nem sempre sejam fáceis de interpretar, em muitos casos você pode pensar nelas como uma predição tentativa sobre a próxima palavra.
As redes feed-forward operam com matemática vetorial
Uma pesquisa recente da Universidade Brown revelou um exemplo elegante de como as camadas feed-forward ajudam a prever a próxima palavra. Anteriormente, discutimos a pesquisa word2vec do Google, que mostrou ser possível usar aritmética vetorial para raciocinar por analogia. Por exemplo, Berlim - Alemanha + França = Paris.
Os pesquisadores da Brown descobriram que, às vezes, as camadas feed-forward usam esse método exato para prever a próxima palavra. Por exemplo, eles examinaram como o GPT-2 respondeu à seguinte instrução, ou prompt em inglês: “Pergunta: Qual é a capital da França? Resposta: Paris. Pergunta: Qual é a capital da Polônia? Resposta:”.
A equipe estudou uma versão do GPT-2 com 24 camadas. Após cada camada, os cientistas da Brown sondaram o modelo para observar sua melhor suposição para o próximo token. Nas 15 primeiras camadas, a suposição principal era uma palavra aparentemente aleatória. Entre a 16ª e a 19ª camada, o modelo começou a prever que a próxima palavra seria Polônia, não corretamente, mas aproximando-se. Então, na 20ª camada, a suposição principal mudou para Varsóvia — a resposta correta — e permaneceu assim nas últimas quatro camadas.
Os pesquisadores da Brown descobriram que a 20ª camada feed-forward converteu Polônia em Varsóvia ao adicionar um vetor que mapeia vetores de países com suas capitais correspondentes. Adicionando o mesmo vetor à China, resultou em Pequim.
As camadas feed-forward no mesmo modelo usaram aritmética vetorial para transformar palavras minúsculas em palavras maiúsculas e palavras no tempo presente em seus equivalentes no tempo passado.
As camadas de atenção e as camadas feed-forward têm trabalhos diferentes
Até agora, analisamos dois exemplos reais de previsões de palavras do GPT-2: cabeças de atenção ajudando a prever que John deu uma bebida para Mary e uma camada feed-forward ajudando a prever que Varsóvia era a capital da Polônia.
No primeiro caso, Mary veio do prompt fornecido pelo usuário. Mas, no segundo caso, Varsóvia não estava no prompt. Em vez disso, o GPT-2 teve que "lembrar" o fato de que Varsóvia era a capital da Polônia — informação que ele aprendeu dos dados de treinamento.
Quando os pesquisadores da Brown desativaram a camada feed-forward que converteu Polônia em Varsóvia, o modelo não previu mais Varsóvia como a próxima palavra. Mas, interessantemente, se eles adicionarem a frase "A capital da Polônia é Varsóvia" no início do prompt, então o GPT-2 poderia responder à pergunta novamente. Isso provavelmente aconteceu porque o GPT-2 usou cabeças de atenção para copiar o nome Varsóvia do início do prompt.
Essa divisão de trabalho é mais geral: cabeças de atenção recuperam informações das palavras anteriores em um prompt, enquanto camadas feed-forward permitem que modelos de linguagem "lembrem" informações que não estão no prompt.
De fato, uma maneira de pensar nas camadas feed-forward é como um banco de dados de informações que o modelo aprendeu de seus dados de treinamento. As camadas feed-forward iniciais são mais propensas a codificar fatos simples relacionados a palavras específicas, como "Trump frequentemente vem depois de Donald". As camadas posteriores codificam relacionamentos mais complexos, como "adicionar este vetor para converter um país em sua capital".
Como os modelos de linguagem são treinados
Muitos dos primeiros algoritmos de machine learning exigiam que os exemplos de treinamento fossem rotulados manualmente por seres humanos. Por exemplo, os dados de treinamento poderiam ser fotos de cães ou gatos com um rótulo fornecido pelo humano ("cão" ou "gato") para cada foto. A necessidade de humanos rotularem os dados tornava difícil e caro criar conjuntos de dados grandes o suficiente para treinar modelos poderosos.
Uma inovação dos LLMs é que eles não precisam de dados explicitamente rotulados. Em vez disso, eles aprendem tentando prever a próxima palavra em passagens de texto. Praticamente qualquer material escrito — de páginas da Wikipédia a artigos de notícias ou código de computador — é adequado para treinar esses modelos.
Por exemplo, um LLM poderia receber a entrada "Eu gosto do meu café com creme e" e deveria prever "açúcar" como a próxima palavra. Um modelo de linguagem recém-inicializado será muito ruim nisso porque cada um de seus parâmetros de peso — 175 bilhões deles na versão mais poderosa do GPT-3 — começará como um número essencialmente aleatório.
Mas conforme o modelo vê mais exemplos — centenas de bilhões de palavras — esses pesos são gradualmente ajustados para fazer previsões cada vez melhores.
Aqui está uma analogia para ilustrar como isso funciona. Suponha que você vai tomar um banho e quer que a temperatura esteja perfeita: nem muito quente, nem muito fria. Você nunca usou esta torneira antes, então aponta a alavanca para uma direção aleatória e sente a temperatura da água. Se estiver muito quente, você a gira para um lado; se estiver muito fria, você a gira para o outro lado. Quanto mais próximo você chega da temperatura certa, menores são os ajustes que você faz.
Agora vamos fazer algumas mudanças na analogia. Primeiro, imagine que há 50.257 torneiras em vez de apenas uma. Cada torneira corresponde a uma palavra diferente, como o, gato ou banco. Seu objetivo é fazer com que a água saia apenas da torneira correspondente à próxima palavra em uma sequência.
Em segundo lugar, há um labirinto de tubos interconectados atrás das torneiras e esses tubos têm um monte de válvulas também. Então, se a água sair da torneira errada, você não ajusta apenas a alavanca na torneira. Você envia um exército de esquilos inteligentes para rastrear cada tubo por trás e ajustar cada válvula que encontram no caminho.
Isso fica complicado porque o mesmo tubo muitas vezes alimenta várias torneiras. Então é necessário um pensamento cuidadoso para descobrir quais válvulas apertar e quais afrouxar, e o quanto.
Obviamente, esta analogia rapidamente se torna absurda se levada muito literalmente. Não seria realista ou útil construir uma rede de tubos com 175 bilhões de válvulas. Mas graças à Lei de Moore, os computadores podem e operam nesse tipo de escala.
Todas as partes dos LLMs que discutimos neste artigo até agora — os neurônios nas camadas feed-forward e as cabeças de atenção que movem informações contextuais entre palavras — são implementadas como uma cadeia de funções matemáticas simples (principalmente multiplicações de matrizes) cujo comportamento é determinado por parâmetros de peso ajustáveis. Assim como os esquilos na minha história afrouxam e apertam as válvulas para controlar o fluxo de água, o algoritmo de treinamento aumenta ou diminui os parâmetros de peso do modelo de linguagem para controlar como a informação flui através da rede neural.
O processo de treinamento acontece em duas etapas. Primeiro, há um "passo para frente", onde a água é ligada e você verifica se ela sai pela torneira certa. Então, a água é desligada e há um "passo para trás", onde os esquilos correm ao longo de cada tubo apertando e afrouxando válvulas. Em redes neurais digitais, o papel dos esquilos é desempenhado por um algoritmo chamado retropropagação, ou backpropagation em inglês, que "anda para trás" através da rede, usando cálculos para estimar quanto mudar cada parâmetro de peso.5
Completar este processo — fazer o passo para frente com um exemplo e depois o passo para trás para melhorar o desempenho da rede neste exemplo — requer centenas de bilhões de operações matemáticas. E treinar um modelo tão grande quanto o GPT-3 requer repetir o processo bilhões de vezes — uma vez para cada palavra dos dados de treinamento.6 A OpenAI estima que foram necessários mais de 300 bilhões de trilhões de cálculos de ponto flutuante para treinar o GPT-3 — isso significa meses de trabalho para dezenas de chips de computador de alto desempenho.
O surpreendente desempenho do GPT-3
Pode ser surpreendente que o processo de treinamento funcione tão bem quanto funciona. O ChatGPT pode realizar todos os tipos de tarefas complexas - escrever ensaios, fazer analogias e até mesmo escrever código de computador. Então, como é que um mecanismo de aprendizado tão simples produz um modelo tão poderoso?
Uma razão é a escala. É difícil exagerar o grande número de exemplos que um modelo como o GPT-3 vê. O GPT-3 foi treinado em um corpus de aproximadamente 500 bilhões de palavras. Para comparação, uma criança humana típica encontra cerca de 100 milhões de palavras até os 10 anos de idade.
Nos últimos cinco anos, a OpenAI aumentou constantemente o tamanho de seus modelos de linguagem. Em um artigo amplamente lido em 2020, a OpenAI relatou que a precisão de seus modelos de linguagem escalou "como uma lei de potência com o tamanho do modelo, tamanho do conjunto de dados e quantidade de computação usada para treinamento, com algumas tendências abrangendo mais de sete ordens de magnitude".
Quanto maiores ficavam seus modelos, melhor eles eram em tarefas envolvendo linguagem. Mas isso só era verdade se aumentassem a quantidade de dados de treinamento por um fator semelhante. E para treinar modelos maiores com mais dados, você precisa de muito mais poder de computação.
O primeiro LLM da OpenAI, o GPT-1, foi lançado em 2018. Ele usava vetores de palavras de 768 dimensões e tinha 12 camadas, totalizando 117 milhões de parâmetros. Alguns meses depois, a OpenAI lançou o GPT-2. Sua versão maior tinha vetores de palavras de 1.600 dimensões, 48 camadas e um total de 1,5 bilhão de parâmetros.
Em 2020, a OpenAI lançou o GPT-3, que apresentava vetores de palavras de 12.288 dimensões e 96 camadas, totalizando 175 bilhões de parâmetros.
Finalmente, em 2023, a OpenAI lançou o GPT-4. A empresa não publicou detalhes arquiteturais, mas acredita-se amplamente que o GPT-4 seja significativamente maior que o GPT-3.
Cada modelo não apenas aprendeu mais fatos do que seus predecessores menores, mas também se saiu melhor em tarefas que exigiam algum tipo de raciocínio abstrato.
Por exemplo, considere a seguinte história:
Aqui está uma sacola cheia de pipoca. Não há chocolate na sacola. No entanto, o rótulo da sacola diz "chocolate" e não "pipoca". Sam encontra a sacola. Ela nunca viu a sacola antes. Ela não pode ver o que está dentro da sacola. Ela lê o rótulo.
Você provavelmente pode adivinhar que Sam acredita que a sacola contém chocolate e ficará surpresa ao descobrir pipoca dentro. Os psicólogos chamam essa capacidade de raciocinar sobre os estados mentais de outras pessoas de "teoria da mente". A maioria das pessoas tem essa capacidade desde a época da escola primária. Especialistas discordam se algum animal não humano (como chimpanzés) possui teoria da mente, mas há um consenso geral de que é importante para a cognição social humana.
No início deste ano, o psicólogo de Stanford Michal Kosinski publicou pesquisas examinando a capacidade dos LLMs de resolver tarefas de teoria da mente. Ele deu a vários modelos de linguagem textos como os que citamos acima e depois pediu que completassem uma frase como "ela acredita que a sacola está cheia de". A resposta correta é "chocolate", mas um modelo de linguagem pouco sofisticado poderia dizer "pipoca" ou algo diferente.
O GPT-1 e o GPT-2 falharam nesse teste. Mas a primeira versão do GPT-3, lançada em 2020, acertou quase 40 por cento das vezes - um nível de desempenho que Kosinski compara ao de uma criança de três anos. A versão mais recente do GPT-3, lançada em novembro passado, melhorou isso para cerca de 90 por cento - no nível de uma criança de sete anos. O GPT-4 respondeu corretamente cerca de 95 por cento das perguntas de teoria da mente.
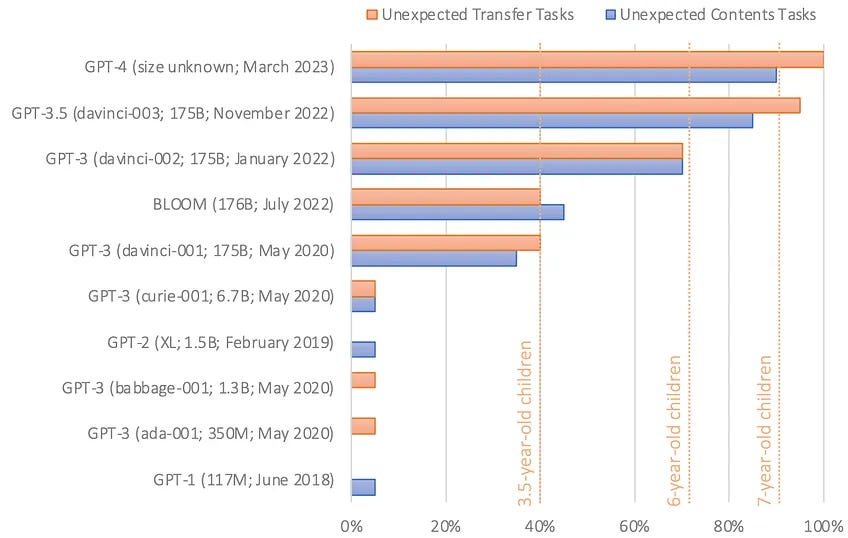
"Dado que não há indicação de que a capacidade semelhante à teoria da mente foi deliberadamente projetada nesses modelos, nem pesquisas demonstrando que os cientistas sabem como alcançá-la, a capacidade semelhante à teoria da mente provavelmente emergiu espontânea e autonomamente, como um subproduto da crescente capacidade de linguagem dos modelos", escreveu Kosinski.
Vale ressaltar que os pesquisadores não concordam se esses resultados indicam evidências de Teoria da Mente: por exemplo, pequenas alterações na tarefa de crença falsa levaram a um desempenho muito pior pelo GPT-3; e o GPT-3 exibe um desempenho mais variável em outras tarefas que medem a teoria da mente. Como um de nós (Sean) escreveu, pode ser que o desempenho bem-sucedido seja atribuído a variáveis de confusão na tarefa - uma espécie de efeito "Hans esperto", ou clever Hans em inglês, mas em modelos de linguagem em vez de cavalos.7
No entanto, o desempenho quase humano do GPT-3 em várias tarefas projetadas para medir a teoria da mente seria impensável apenas alguns anos atrás - e é consistente com a ideia de que modelos maiores geralmente são melhores em tarefas que exigem raciocínio de alto nível.
Este é apenas um dos muitos exemplos de modelos de linguagem que aparentemente desenvolveram espontaneamente capacidades de raciocínio de alto nível. Em abril, pesquisadores da Microsoft publicaram um artigo argumentando que o GPT-4 mostrou indícios iniciais e tentadores de inteligência artificial geral - a capacidade de pensar de forma sofisticada, semelhante à humana.
Por exemplo, um pesquisador pediu ao GPT-4 para desenhar um unicórnio usando uma linguagem de programação gráfica obscura chamada TiKZ. O GPT-4 respondeu com algumas linhas de código que o pesquisador então inseriu no software TiKZ. As imagens resultantes eram rudimentares, mas mostravam sinais claros de que o GPT-4 tinha algum entendimento de como os unicórnios se parecem.

Os pesquisadores pensaram que o GPT-4 talvez tivesse memorizado de alguma forma o código para desenhar um unicórnio a partir de seus dados de treinamento, então deram a ele um desafio adicional: alteraram o código do unicórnio para remover o chifre e mover algumas outras partes do corpo. Então pediram ao GPT-4 para colocar o chifre de volta. O GPT-4 respondeu colocando o chifre no local certo:

O GPT-4 foi capaz de fazer isso mesmo que os dados de treinamento para a versão testada pelos autores fossem totalmente baseados em texto. Ou seja, não havia imagens em seu conjunto de treinamento. Mas o GPT-4 aparentemente aprendeu a raciocinar sobre a forma do corpo de um unicórnio após o treinamento com uma enorme quantidade de texto.
No momento, não temos uma compreensão real de como os LLMs realizam feitos como este. Algumas pessoas argumentam que exemplos como este demonstram que os modelos estão começando a entender verdadeiramente os significados das palavras em seus dados de treinamento. Outros insistem que os modelos de linguagem são "papagaios estocásticos" que simplesmente repetem sequências de palavras cada vez mais complexas sem realmente entendê-las.
Esse debate aponta para uma tensão filosófica profunda que talvez seja impossível de resolver. No entanto, achamos importante focar no desempenho empírico de modelos como o GPT-3. Se um modelo de linguagem é capaz de consistentemente obter a resposta correta para um tipo específico de pergunta, e se os pesquisadores têm confiança de que controlaram as variáveis de confusão (por exemplo, garantindo que o modelo de linguagem não foi exposto a essas perguntas durante o treinamento), então isso é um resultado interessante e importante, independentemente de ele entender a linguagem exatamente da mesma forma que as pessoas.
Outra possível razão pela qual o treinamento com previsão do próximo token funciona tão bem é que a linguagem em si é previsível. Regularidades na linguagem muitas vezes (embora nem sempre) estão conectadas a regularidades no mundo físico. Portanto, quando um modelo de linguagem aprende sobre as relações entre palavras, muitas vezes está implicitamente aprendendo também sobre as relações no mundo.
Além disso, a previsão pode ser fundamental tanto para a inteligência biológica quanto para a inteligência artificial. Na visão de filósofos como Andy Clark, o cérebro humano pode ser pensado como uma "máquina de previsão", cujo trabalho principal é fazer previsões sobre nosso ambiente que podem então ser usadas para navegar com sucesso nesse ambiente. Intuitivamente, fazer boas previsões se beneficia de boas representações - é mais provável que você navegue com sucesso com um mapa preciso do que com um impreciso. O mundo é grande e complexo, e fazer previsões ajuda os organismos a se orientarem e se adaptarem eficientemente a essa complexidade.
Tradicionalmente, um grande desafio para a construção de modelos de linguagem era descobrir a maneira mais útil de representar diferentes palavras - especialmente porque os significados de muitas palavras dependem muito do contexto. A abordagem de previsão da próxima palavra permite que os pesquisadores contornem esse quebra-cabeça teórico espinhoso, transformando-o em um problema empírico. Acontece que, se fornecermos dados e poder computacional suficientes, os modelos de linguagem acabam aprendendo muito sobre como a linguagem humana funciona simplesmente descobrindo como prever melhor a próxima palavra. A desvantagem é que acabamos com sistemas cujo funcionamento interno não entendemos completamente.
Tim Lee fez parte da equipe da Ars Technica de 2017 a 2021. Recentemente, lançou uma nova newsletter, Understanding AI, no qual explora como a IA funciona e como está mudando nosso mundo.
Sean Trott é um Assistente de Professor na Universidade da Califórnia em San Diego, onde conduz pesquisas sobre o entendimento da linguagem em humanos e grandes modelos de linguagem. Ele escreve sobre estes e outros temas em sua Newsletter, The Counterfactual.
Carlos Dutra é matemático e cientista de dados com experiência nos setores de serviços financeiros, varejo e mobile games. Ele desenvolve modelos de machine learning, processamento de linguagem natural e LLMs, além de contribuir para a divulgação científica de IA no Brasil.
Tecnicamente, os LLMs operam com fragmentos de palavras chamados tokens, mas vamos ignorar esse detalhe de implementação para manter o tamanho do artigo em um nível gerenciável.
Tecnicamente, a versão original do ChatGPT é baseada no GPT-3.5, um sucessor do GPT-3 que passou por um processo chamado Aprendizado por Reforço com Feedback Humano (RLHF). A OpenAI não divulgou todos os detalhes da arquitetura deste modelo, então neste texto vamos nos concentrar no GPT-3, a última versão que a OpenAI descreveu em detalhes.
A rede feed-forward também é conhecida como um perceptron de múltiplas camadas. Cientistas da computação têm explorado esse tipo de rede neural desde a década de 1960.
Tecnicamente, após um neurônio calcular a soma ponderada de suas entradas, ele passa o resultado para uma função de ativação. Vamos ignorar esse detalhe de implementação, mas você pode ler esse artigo de Tim de 2018 se quiser uma explicação completa de como os neurônios funcionam.
Se quiser saber mais sobre backpropagation, veja o artigo de 2018 do Tim sobre como as redes neurais funcionam.
Na prática, o treinamento geralmente é feito em lotes para fins de eficiência computacional. Portanto, o software pode fazer o “passo para frente” em 32.000 tokens antes de fazer o “passo para trás”.
Nota do tradutor: O efeito Hans esperto refere-se à tendência de um animal ou sistema a parecer inteligente ao responder a pistas sutis ou inadvertidas do observador.
 | A guest post by
|