
Why it’s getting harder to measure AI performance
The most famous chart in AI might be obsolete soon.

Before we get to today’s article, I want to recommend some audio content about autonomous vehicles:
Back in 2010, my friend Ryan Avent and I made a bet about the future of autonomous vehicles. The bet came due last month and I won. Ryan and I did a postmortem on my podcast, AI Summer. You can listen here or search for “AI Summer” in your favorite podcast app.
PJ Vogt’s podcast Search Engine just did a two-part series on autonomous vehicles. I’m biased since I was quoted in both episodes, but I thought it was incredibly good. You can listen here, or search for “Search Engine” in your favorite podcast app.
Now for today’s article!
If you’ve followed AI over the last year, you’ve probably seen the famous “METR chart”:
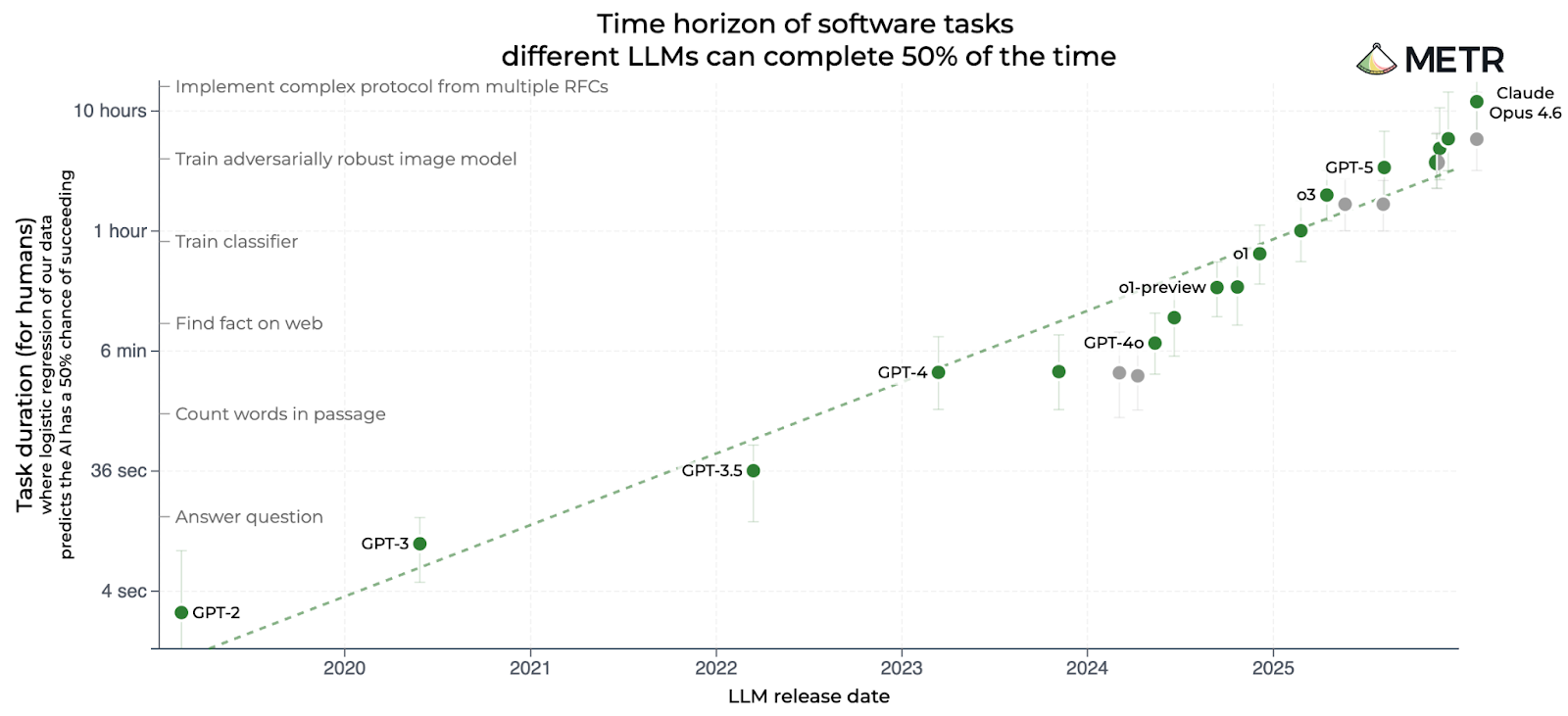
METR, short for Model Evaluation and Threat Research, is based in Berkeley, California. The group has published many charts, but this one has become its calling card. It compares AI models based on the complexity of software engineering tasks they can complete, with complexity measured by how long it takes a human programmer to complete the same task:
GPT-3.5 — the model that powered the original ChatGPT — could complete tasks that took a human programmer about 30 seconds.
GPT-4, released in March 2023, bumped that up to 4 minutes.
o1, released in December 2024, was OpenAI’s first “reasoning model.” It could perform tasks that took a human 40 minutes.
GPT-5, released in August 2025, was able to finish tasks that took humans 3 hours.
Claude Opus 4.6 was released in February by Anthropic. METR estimates it can complete tasks that would take a human programmer 12 hours.
That last figure is twice as long as the estimate for the previous leader, GPT-5.2, which had been released just two months earlier.
I think this chart — and especially the impressive score for Claude Opus 4.6 — has done a lot to foster an impression of accelerating AI progress in recent months. Notice that the chart is logarithmic, so a straight line indicates exponential progress. The fact that Claude Opus 4.6 is above the previous trend line suggests very rapid progress indeed.
But if you click on METR’s task length page and hover over the dot for Claude Opus 4.6, you’ll see something interesting: METR’s confidence interval for Claude Opus 4.6 ranges from 5 hours to 66 hours. On Twitter, METR staff have urged people not to take the latest results as gospel.
“When we say the measurement is extremely noisy, we really mean it,” METR’s David Rein wrote.
METR depends on having a mix of easy tasks that an AI model can solve and harder tasks that it can’t. This allows the group to bracket the capabilities of a model. But Claude Opus 4.6 was able to solve some of the hardest problems in METR’s test suite, which made it difficult to put an upper bound on its capabilities.
So we know the latest Claude Opus is better than previous models, but it’s hard to say how much better. This means we don’t know if the apparent acceleration of the last few months is real or just a statistical artifact.
METR could — and perhaps will — add harder tasks to its test suite so it can test future models with greater precision.
But there’s also a deeper philosophical challenge.
Like most AI benchmarks, this one measures AI performance using tasks that are well-defined, self-contained, and easily verified. But a lot of the tasks humans perform aren’t like this.
In real workplaces, tasks are often connected to other tasks. They frequently require interacting with other people or the outside world. Sometimes it’s not clear what task needs doing, and goals may evolve as people work on a project. Even after a task is completed, people might not agree on whether it was done well.
Complexities like this will become more important as AI models tackle longer tasks — tasks that take weeks or months rather than just hours. We don’t have great ways to measure the performance of AI models on these kinds of tasks — in part because we struggle to judge the performance of human workers in the same situations.
As a consequence, we may see a growing divergence between the capabilities we can measure and the capabilities we actually care about.
The life cycle of an AI benchmark
In the early years of large language models, it was common for people to cite a benchmark called MMLU, short for Massive Multitask Language Understanding. It grills a language model on a wide range of topics: history, computer science, genetics, astronomy, international law, and more.
When MMLU was published in 2020, the best-performing LLM was GPT-3. It scored 43.9%. An older model, GPT-2, scored 32.4% — not much better than the 25% score you’d get from random guessing.
By the time I started writing about LLMs in 2023, GPT-4 had scored 86.4%. GPT-4o scored 88.7% in 2024, and GPT-4.1 scored 90.2% in 2025.
In the last year, AI companies have stopped reporting MMLU scores — presumably because scores have stopped improving. That’s not surprising; it’s impossible to get a score much higher than 93% without cheating because around 6.5% of MMLU questions contain errors.
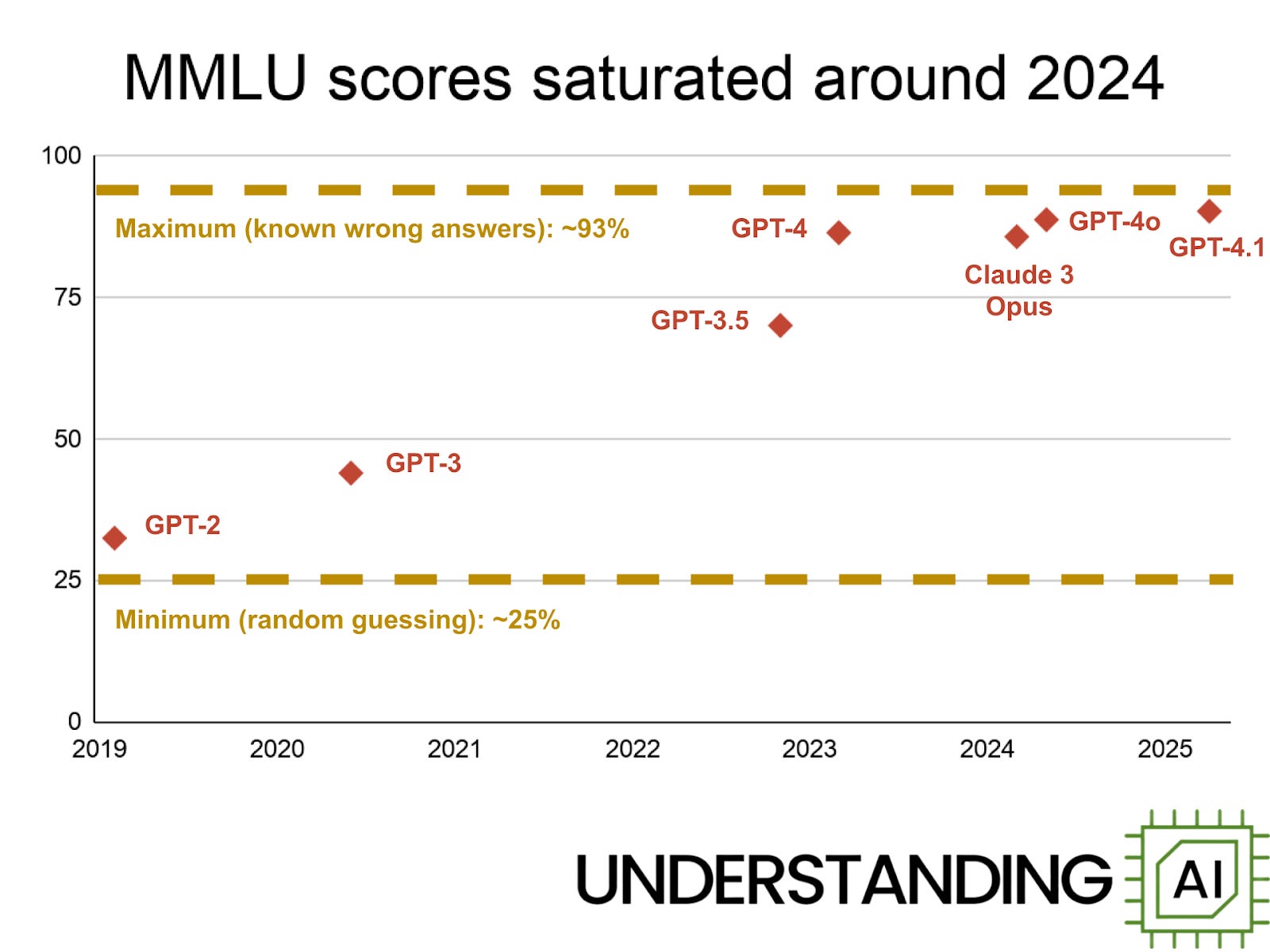
So conventional benchmarks like MMLU have a natural lifecycle. At first, most problems are beyond models’ capabilities, so scores cluster near the minimum. As models improve, benchmark scores increase until they approach the theoretical maximum. Since 2024, frontier models have all scored between 88% and 93%, a narrow enough range that differences could be random noise. In industry jargon, MMLU has saturated.
Over time, the AI community works to develop more difficult benchmarks to replace earlier ones that have saturated. For example, in early 2025 Dan Hendrycks, the lead author of MMLU, co-authored a new, more difficult benchmark called Humanity’s Last Exam (HLE). Like MMLU, HLE includes questions in subjects ranging from chemistry to law.
When it was released, the best model was o3-mini (high), which scored 13.4% on HLE. Today, the leading model is Google’s Gemini 3.1, which scored 44.7%. Perhaps in a year or two models will begin to saturate this benchmark, with gains slowing as they approach 100%.
METR created a different kind of benchmark
We know that HLE is harder than MMLU, but it’s difficult to say how much harder. There’s no obvious way to compare scores across different benchmarks, which makes it hard to compare model capabilities over long time periods — or to make predictions about future models.
METR invented a clever solution to this problem. Its benchmark contains tasks with a wide range of difficulties. The easiest problems are designed to take humans a few seconds — for example, a simple factual question about the syntax of a programming language. The hardest problems would take a human programmer many hours.
METR didn’t just guess how long humans would take on these tasks; it hired programmers and measured their actual completion times.1 For example, one problem in the METR test suite was to “speed up a Python backtesting tool for trade executions by implementing custom CUDA kernels while preserving all functionality.” METR found that this takes human programmers about eight hours.
Measuring tasks this way gives us a way to compare models with dramatically different capabilities. GPT-2 could only complete tasks that took human programmers about two seconds, whereas GPT-5 could complete tasks that took around 3 hours of human effort. So we could say that GPT-5 could complete tasks that are 5,400 times “harder” than the tasks GPT-2 could complete.
If this pace of progress continues — doubling task length every six or seven months — we should expect LLMs capable of completing week-long tasks (that is, 40 hours of human labor) some time next year, and month-long tasks (four 40-hour weeks) in 2028.2
However, the current version of METR’s task-length benchmark wouldn’t be able to meaningfully test such a powerful model. The most difficult tasks in the current test suite — such as “fix a control algorithm for a 4-wheeled omni-directional robot to follow cubic splines quickly despite wheel slippage and motor jerk limitations” — take humans about 30 hours to complete.
In other words, METR’s task-length benchmark is close to saturating.
METR’s benchmark gets a little crazy when it saturates
We saw earlier that when conventional benchmarks saturate, scores start to cluster around a maximum value — like 93% for MMLU. METR’s benchmark works differently. When a model starts solving the hardest questions, the benchmark’s confidence interval widens dramatically because there is no way to place an upper bound on model performance. As I noted previously, METR’s confidence interval for Claude Opus 4.6 ranges from 5 to 66 hours.
“If we took one task out of our task suite or added another task to our task suite, potentially instead of measuring this Claude Opus 4.6 time horizon of, I think, 14 and a half hours, we’d be measuring it at something like eight or 20 hours,” METR’s Joel Becker told me in a recent interview on my podcast. “That’s how sensitive things are now to a single task.”
In principle, the solution is simple: add tasks that take human programmers more than 30 hours. Ideally, METR would test models on tasks that take humans 40 hours, 80 hours, 160 hours, and so forth. That would extend the useful life of the benchmark by at least a couple more years.
But this won’t be easy. METR pays human programmers a minimum of $50 per hour, so getting a baseline for a single 160-hour task would cost at least $8,000. And that’s assuming they can even convince programmers to participate. I bet METR would struggle to find experienced programmers willing to tackle tasks that stretch across multiple weeks; many programmers would have to quit their day jobs to make time.
There’s also a deeper conceptual problem with trying to extend the METR benchmark — or any benchmark like it — to tasks that require dozens of hours of human work.
Keep reading with a 7-day free trial
Subscribe to Understanding AI to keep reading this post and get 7 days of free access to the full post archives.