
Google and Anthropic approach LLMs differently
The very different cultures of OpenAI's two most important rivals.

On Monday, OpenAI CEO Sam Altman declared a “code red” in the face of rising competition.
The biggest threat was Google; monthly active users for Google’s Gemini chatbot grew from 450 million in July to 650 million in November (ChatGPT had 800 million weekly active users in October). Meanwhile, the Wall Street Journal reports, “OpenAI is also facing pressure from Anthropic, which is becoming popular among business customers.”
Google ratcheted up the pressure on OpenAI two weeks ago with the release of Gemini 3 models, which set new records on a number of benchmarks. The next week, Anthropic released Claude Opus 4.5, which achieved even higher scores on some of the same benchmarks.
Over the last two weeks, I’ve been trying to figure out the best way to cover these new releases. I used to subject each new model to a battery of bespoke benchmarks and write about the results. But recent models have gotten good enough to easily solve most of these problems. They do still fail on a few simple tasks (like telling time on an analog clock) but I fear those examples are increasingly unrepresentative of real-world usage.
In the future, I hope to write more about the performance of these new Google and Anthropic models. But for now, I want to offer a more qualitative analysis of these models. Or rather, I want to highlight two pieces that illustrate the very different cultures at Google and Anthropic — cultures that have led them to take dramatically different approaches to model building.
Engineering excellence at Google

Last week the newsletter Semianalysis published a deep dive on the success of tensor processor units (TPUs), Google’s alternative to Nvidia GPUs. “Gemini 3 is one of the best models in the world and was trained entirely on TPUs,” the Semianalysis authors wrote. Notably, Claude Opus 4.5 was also trained on TPUs.
Google has employed TPUs for its own AI needs for a decade. But recently Google has made a serious effort to sell TPUs to other companies. The Semianalysis team argues that Google is “the newest and most threatening merchant silicon challenger to Nvidia.”
In October, Anthropic signed a deal to use up to one million TPUs. In addition to purchasing cloud services from Google, Semianalysis reported, “Anthropic will deploy TPUs in its own facilities, positioning Google to compete directly with Nvidia.”
Recent generations of the TPU were respectable chips, but Semianalysis argues Google’s real strength is the overall system architecture. Modern AI training runs require thousands of chips wired together for rapid communication. Google has designed racks and networking systems that squeeze maximum performance out of every chip.
This is one example of a broader principle: Google is fundamentally an engineering-oriented company, and it has approached large language models as an engineering problem.1 Engineers have worked hard to train the largest possible models at the lowest possible cost.
For example, Gemini 2.5 Flash-Lite costs 10 cents for a million input tokens. Anthropic’s cheapest model, Claude Haiku 4.5, costs 10 times as much. Google was also the first company to release an LLM with a million-token context window.
Another place Google’s engineering prowess has paid off is in pretraining. Google released this chart showing Gemini 3 crushing other models at SimpleQA, a benchmark that measures a model’s ability to recall obscure facts.
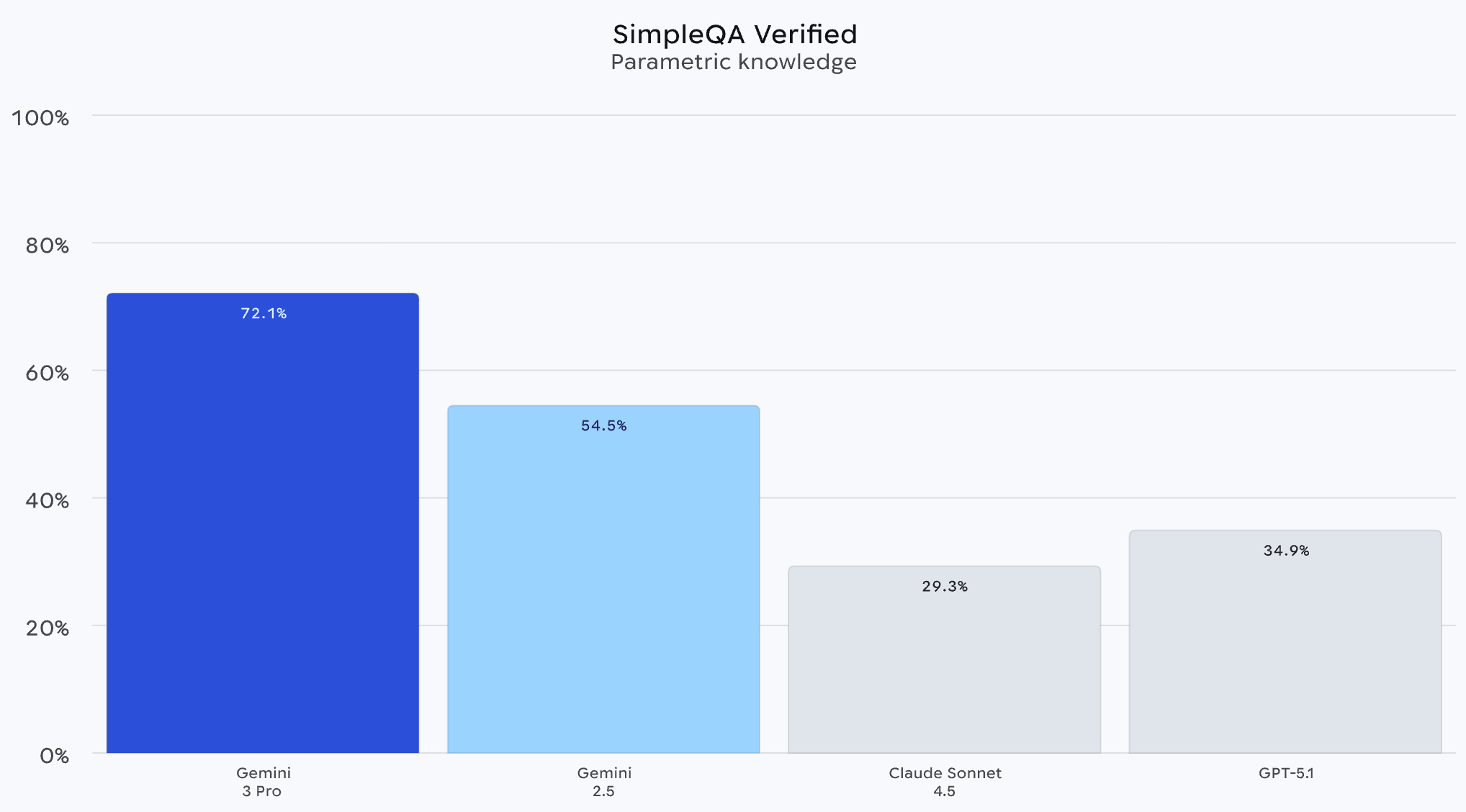
As a perceptive Reddit commenter points out, this likely reflects Google’s ability to deploy computing hardware on a large scale.
“My read is that Gemini 3 Pro’s gains in SimpleQA show that it’s a massive model, absolutely huge, with tons of parametric knowledge,” wrote jakegh. “Google uses its own TPU hardware to not only infer but also train so they can afford to do it.”
So Gemini 3 continues the Google tradition of building solid, affordable models. Public reaction to the new model has been broadly positive; the model seems to perform as well in real-world applications as it does on benchmarks.
The new model doesn’t seem to have much personality, but this may not matter. Billions of people already use Google products, so Google may be able to win the AI race simply by adding a good-but-not-amazing model like Gemini 3 to products like search, Gmail, and the Google Workspace suite.
Anthropic: thinking deeply about models
Last week’s release of Claude Opus 4.5 also got a positive reception, but the vibes were different.
Keep reading with a 7-day free trial
Subscribe to Understanding AI to keep reading this post and get 7 days of free access to the full post archives.