
The best Chinese open-weight models — and the strongest US rivals
The Understanding AI guide to open-weight models.

DeepSeek’s release of R1 in January shocked the world. It came just four months after OpenAI announced its first reasoning model, o1. The model parameters were released openly. And DeepSeek R1 powered the first consumer-facing chatbot to show the full chain of thought before answering.
The effect was electric.
The DeepSeek app briefly surpassed ChatGPT as the top app in the iOS App Store. Nvidia’s stock dropped almost 20% a few days later. Chinese companies rushed to use the model in their products.
DeepSeek’s success with R1 sparked a renaissance of open-weight efforts from Chinese companies. Before R1, Meta’s Llama models were the most prominent open-weight models. Today, Qwen, from the e-commerce firm Alibaba, is the leading open model family. But it faces stiff competition from DeepSeek, Moonshot AI, Z.AI, and other (primarily Chinese) companies.
American companies have also released a number of notable open-weight models. OpenAI released open-weight models in August. IBM officially released its well-regarded Granite 4 models in October. Google, Microsoft, Nvidia, and the Allen Institute for AI have all released new open models this year — and so has the French startup Mistral. But none of these models have been as good as the top Chinese models.
With so many releases, which ones are worth paying attention to?
In this piece, I’ll cover 13 of the most significant open-weight model developers, starting with the models that deliver the most bang for the buck. For each company, I’ll list a few models worth paying attention to, using Intelligence Index scores from Artificial Analysis as a rough approximation of model quality.
A key inspiration for this article has been Nathan Lambert, a researcher at the Allen Institute for Artificial Intelligence and the author of the excellent Interconnects newsletter. Lambert is concerned about the slow progress of American open-weight models and has been trying to rally support for building a new generation of open-weight models in the US. You can read about that effort here.
1. Qwen from Alibaba
Takeaway: There’s a very good Qwen model at basically every size through 235 billion parameters. The fact that Qwen is Chinese might be the biggest barrier for the average US firm.
Models:
Qwen3 4B Thinking:
Released April 26, 2025
Intelligence Index: 43
Qwen3 VL 32B:
Released October 19, 2025
Intelligence Index: 52
Qwen3 Next 80B:
Released September 9, 2025
Intelligence Index: 54
Qwen3 235B A22B 2507:1
Released July 25, 2025
Intelligence Index: 57
The Qwen family of open-weight models is made by Alibaba, an e-commerce and cloud services tech company.
Qwen models come in many sizes. As Nathan Lambert noted in a talk at the PyTorch conference, “Qwen alone is roughly matching the entire American open model ecosystem today.”
Enterprises often need to execute a series of simple tasks as part of a larger data pipeline. Open models — especially Qwen models — tend to work well here. The company has excelled at producing small models that run on cheap hardware.
The Qwen series faces stiffer open-weight competition at the large end of the spectrum. And the largest Qwen model — Qwen3-Max — is not open-weight.
There’s a robust community around Qwen models. According to an analysis of Hugging Face data by the ATOM Project, Qwen is now the most downloaded model family in the world.
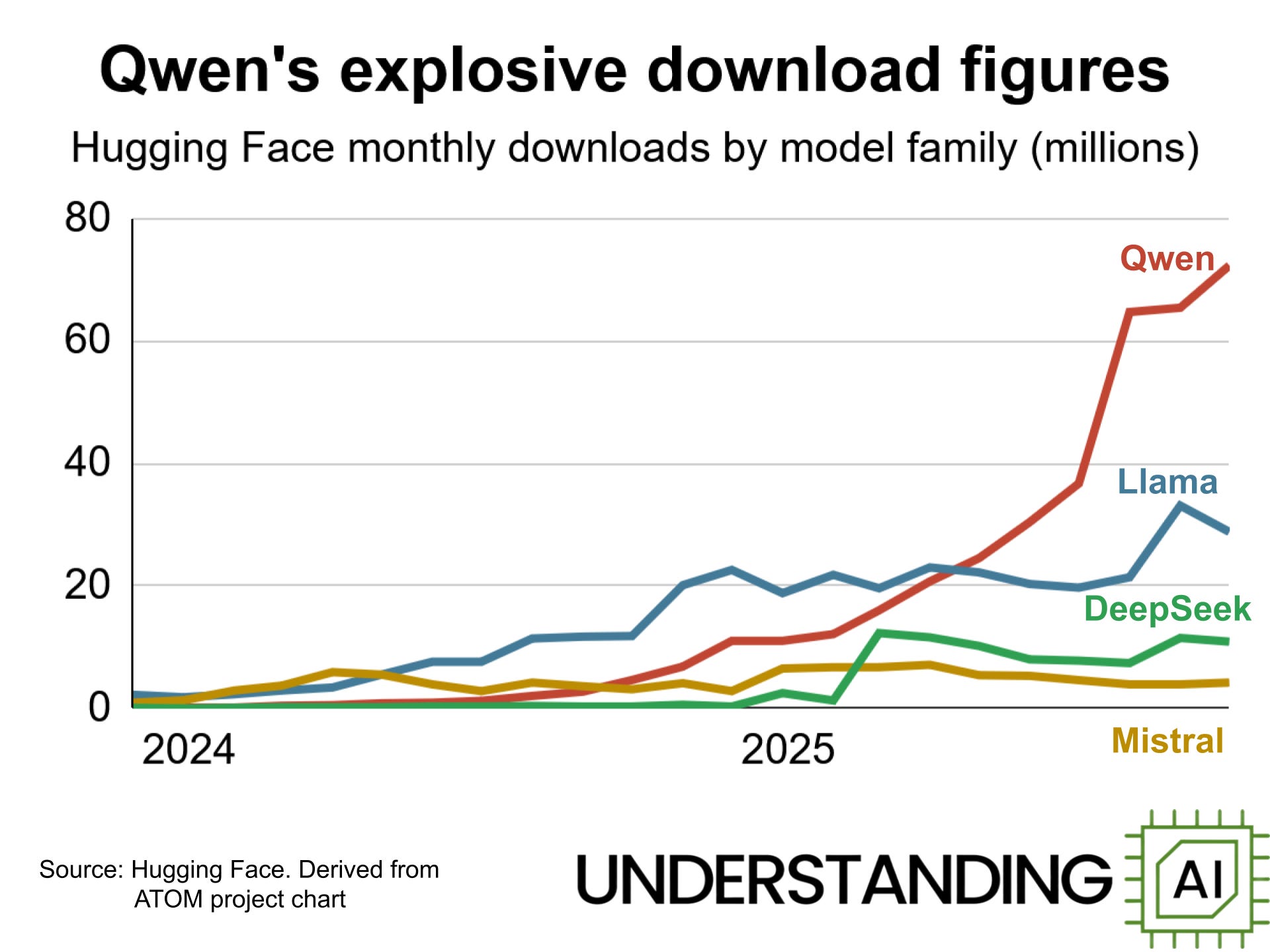
There have also been whispers of American companies adopting Qwen models. In October, Airbnb CEO Brian Chesky caused a stir by telling Bloomberg that the company is “relying a lot on Alibaba’s Qwen model” because it is fast, cheap, and performant enough.
But I spoke with several people whose organizations could not use Qwen (and other Chinese open models) for branding or compliance reasons.
This is one of the biggest barriers to Qwen’s adoption, as Lambert wrote in May:
People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions built by people who know the fact that model weights alone cannot reveal anything to their creators.
Lambert argues that many companies worry about the output of Chinese models being compromised. With current techniques, it’s impossible to rule this out without access to the training data — though Lambert believes the models are probably safe.
2. Kimi K2 from Moonshot
Takeaway: Kimi K2 Thinking is arguably the best open model in the world, but it’s difficult to run locally.
Models:
Kimi K2 0905 (1 trillion parameters):
Released September 2, 2025
Intelligence Index: 50
Kimi K2 Thinking (1T):
Released November 4, 2025
Intelligence Index: 67
Moonshot AI is a Chinese startup founded in March 2023. Kimi K2 is their flagship large language model.
Kimi K2 Thinking is arguably the best open model in the world by benchmark score. Artificial Analysis currently ranks it as the strongest model not made by OpenAI, Google, or Anthropic. Epoch’s Capabilities Index ranks it as the second best open model, and 14th overall.
Beyond the benchmarks, most reactions to Kimi have been positive.
Many people have praised K2’s writing abilities, both as a reasoning model and not. Rohit Krishnan, an entrepreneur and Substacker, tweeted that “Kimi K2 is remarkably good at writing, and unlike all others thinking mode hasn’t degraded its writing ability more.”
Nathan Lambert noted that Kimi K2 Thinking is one of the first open-weight models to be able to make long strings of tool calls, several hundred at a time. This makes agentic workflows possible.
On a podcast, Chamath Palihapitiya, a venture capitalist and former Facebook executive, said that his company 8090 has “directed a ton of our workloads to Kimi K2 on Groq because it was really way more performant and frankly just a ton cheaper than OpenAI and Anthropic.”
Some Reddit commenters have noted that K2 Thinking is not quite as strong at agentic coding as other open-weight models like Qwen coding models or Z.AI’s GLM, but it’s still a solid option and a stronger all-around model.
Kimi K2 also uses a lot of tokens; of all the models listed in this piece, K2 Thinking uses the second most tokens on Artificial Analysis’s benchmark suite.
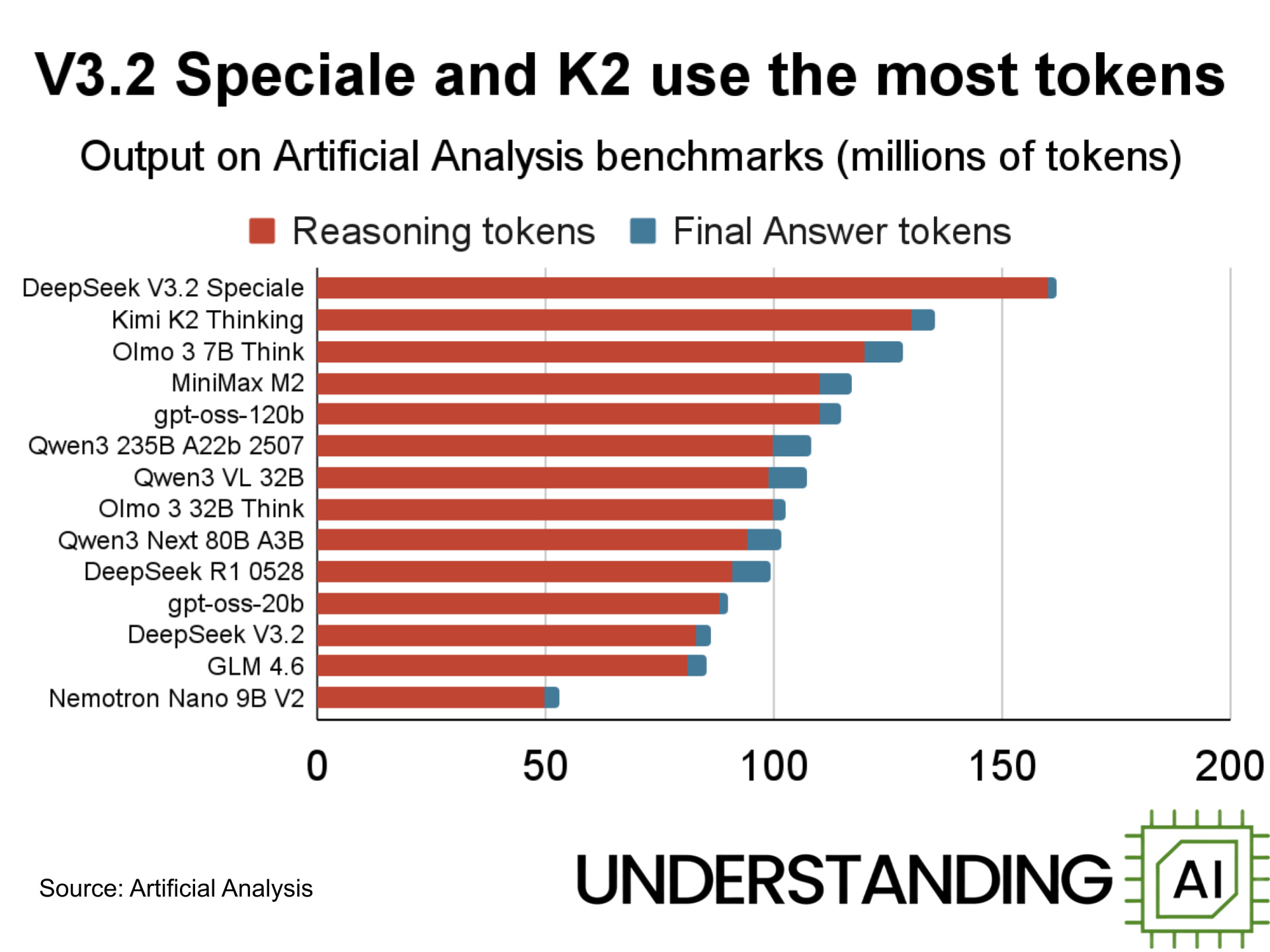
And good luck trying to run this on your own computer. K2 Thinking has more than one trillion parameters, and the Hugging Face download is over 600 GB. One Redditor managed to get a quantized version running on a personal computer (with a GPU attached) at the speed of … half a token per second.
So in practice, using Kimi requires Moonshot’s API service, a third-party inference provider, or your own cluster.
3. gpt-oss from OpenAI
Takeaway: The gpt-oss models are excellent at reasoning tasks, and very fast. But they are weaker outside of pure reasoning tasks.
Models:
gpt-oss-20b:
Released August 4, 2025
Intelligence Index: 52 on high reasoning, 44 on low reasoning
gpt-oss-120b:
Released August 4, 2025
Intelligence Index: 61 on high reasoning, 48 on low reasoning
In August, OpenAI released two open-weight models, gpt-oss-120b and gpt-oss-20b. The 120b version is almost certainly the most capable American open model.
Both models are optimized for reasoning and agentic tasks — OpenAI claimed they were at “near-parity with OpenAI o4-mini on core reasoning benchmarks.” This includes math; the fourth-best-performing entry in the Kaggle competition to solve IMO-level problems — which currently has a $2.5 million prize pot — is based on gpt-oss-120b. (It’s unclear what models are used by entries one through three.)
The gpt-oss models have a generally solid reputation. “When I ask people who work in these spaces, the impression has been very positive,” Nathan Lambert noted in a recent talk on the state of open models.
They are also very fast. A Reddit commenter benchmarking various models was able to run gpt-oss-20b locally at 224 tokens per second, faster than the GPT-5.1, Gemini, or Claude APIs. And according to Artificial Analysis, some inference providers can run the 120B variant at over 3,000 tokens per second.
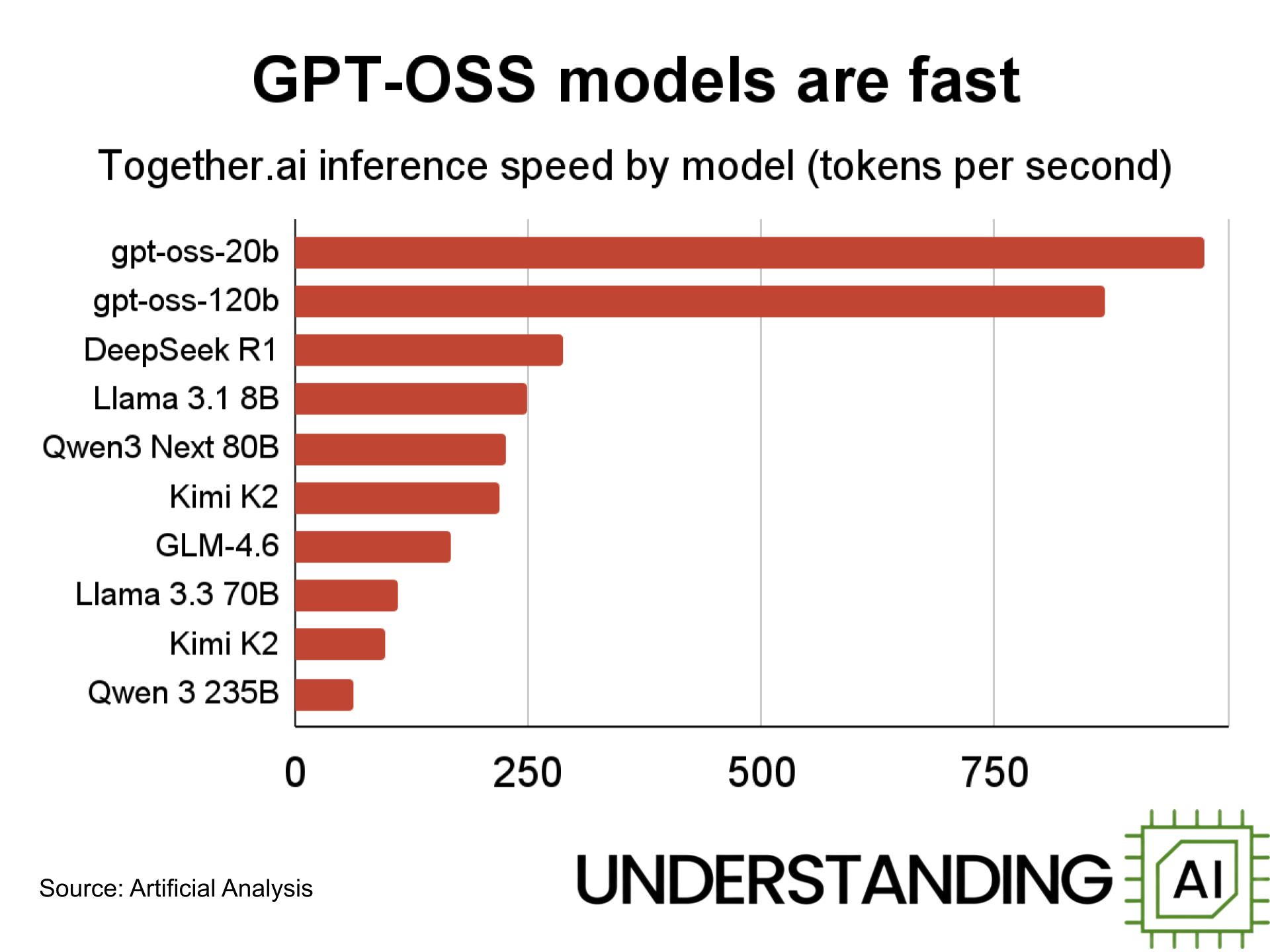
However, the gpt-oss models aren’t as good outside of coding, math, and reasoning. In particular, they have little factual knowledge. On SimpleQA, gpt-oss-120b only gets 16.8% right and gpt-oss-20b gets a mere 6.7% right. (Gemini 3 Pro gets 70% right, while GPT-5.1 gets 50% right). And when they get stumped by a SimpleQA question, the gpt-oss models almost always hallucinate an answer.
It’s also unclear whether OpenAI will release a follow-up to these two models. In the meantime, it’s a solid choice for reasoning and coding tasks if you need an American model you can run locally.
4. The DeepSeek models
Takeaway: DeepSeek releases strong models, particularly in math. Its most recent release, V3.2, is solid but not exceptional. Future releases might be a big deal.
Models:
DeepSeek R1 0528 (685 billion parameters):
Released May 28, 2025
Intelligence Index: 52
DeepSeek V3.2 (685B):
Released December 1, 2025
Intelligence Index: 66
DeepSeek V3.2 Speciale (685B):
Released December 1, 2025
Intelligence Index: 59
DeepSeek is an AI company owned by the Chinese hedge fund HighFlyer. DeepSeek explicitly aims to develop artificial general intelligence (AGI) through open models. As I mentioned in the introduction, the success of DeepSeek R1 in January inspired many open-weight efforts in China.
At the beginning of December, DeepSeek released V3.2 and V3.2 Speciale. These models have impressive benchmark numbers: Artificial Analysis rates V3.2 as the second best open model on their index, while V3.2 Speciale tops all models — open or closed — in the MathArena benchmark for final answer competitions.
Still, DeepSeek’s recent releases haven’t seemed to catch the public’s attention. Substack writer Zvi Mowshowitz summed up V3.2 as “okay and cheap but slow.” Mowshowitz noted there had not been much public adoption of the model.
It’s also probably a good idea to use DeepSeek’s products through an American provider or on your own hardware. In February, a security firm found that DeepSeek’s website was passing information to a Chinese state-owned company. (It’s unclear whether this is still happening.)
Regardless of how V3.2 fares, DeepSeek will remain a lab to watch. Their next major model release (rumored to be in February 2026) might be a big deal.
5. Olmo 3 from the Allen Institute for AI
Takeaway: Olmo 3 models are open-source, not just open-weight. Their performance isn’t too far behind Qwen models.
Models:
Olmo 3 7B:
Released November 20, 2025
Intelligence Index: 32 for thinking, 22 for instruct
Olmo 3.1 32B Think:
Released December 12, 2025
Intelligence Index: Not yet benchmarked, but Olmo 3 32B Think was 36
The Allen Institute for Artificial Intelligence (Ai2) is a nonprofit research institute founded in 2014. The Olmo series is one of Ai2’s main research products.
Olmo 3, released in November, is probably the best open-source model in the world. Every other developer I discuss here (except Nvidia) releases only open-weight models, where the final set of model parameters is available but not the code and data used for training. Ai2 not only released training code and data, but also several model checkpoints from midway through the training process.
This lets researchers learn from Olmo’s development process, take advantage of the open datasets, and use the Olmo models in their experiments.
Olmo’s openness can also be helpful for enterprise. One of the project’s co-leaders, Hanna Hajishirzi, told me that having several Olmo checkpoints gives companies more flexibility.
Companies can train an earlier Olmo 3 checkpoint to ensure that the model ends up effectively learning from the data for their use case. Hajishirzi said that she hears a lot of people say fine-tuning doesn’t work, but that’s because they’re only training on the “final snapshot of the model.”
For instance, if a model has already gone through reinforcement learning to improve its coding skills, it may have weaker capabilities elsewhere. So if a company wants to fine-tune a model to be good at a non-coding skill — like giving feedback on writing — they are better off choosing an earlier checkpoint.
Still, out of the box, the Olmo 3 models perform a little worse than the best open-weight models of their size, which are the Qwen models. And they’re certainly much weaker than large open-weight models like Kimi K2 Thinking.
In any event, the Allen Institute is an organization to watch. It recently received a $150 million grant from the National Science Foundation and Nvidia to create open models for scientists.
6. GLM 4.6 from Z.AI
Takeaway: The GLM 4.6 models are solid, particularly for coding.
Models:
GLM 4.6V-Flash (10B):
Released December 8, 2025
Intelligence Index score has not been released
GLM 4.6 (357B):
Released September 29, 2025
Intelligence Index: 56
GLM 4.6V (108B):
Released December 8, 2025
Intelligence Index score has not been released
Z.AI (formerly Zhipu AI) is a Chinese AI startup founded in 2019. In addition to its flagship GLM series of LLMs, it also releases some non-text models.
Unlike many of the other startups that form the Six Chinese Tigers, Z.AI was popular in China even before DeepSeek came to prominence. Z.AI released the first version of GLM all the way back in 2021, albeit not as an open model. A market survey in mid-2024 found that Z.AI was the third most popular enterprise LLM provider in China, after Alibaba and SenseTime.
But until recently, Z.AI struggled to attract attention outside of China. Now that is starting to change after two strong releases: GLM 4.5 in July and GLM 4.6 in late September. In November, the South China Morning Post reported that Z.AI had 100,000 users of its API, a “tenfold increase over two months,” and over 3 million chatbot users.
GLM 4.6 is probably not as strong as the best Qwen models, nor Kimi, but it is a very solid option, particularly for coding.
Z.AI may not continue releasing open-weight models if its market position changes.
The company’s product director, Zixuan Li, recently told ChinaTalk that “as a Chinese company, we need to really be open to get accepted by some companies because people will not use your API to try your models.” Z.AI is a startup without a strong pre-existing brand or capital in reserve. Gaining adoption is crucial to the company’s survival. Releasing a model’s weights allows enterprises to try it without having to worry about the data security challenges of using a Chinese API.
Z.AI “only gets maybe 5% or 10% of all the services related to GLM,” according to Li. For now, that’s enough revenue for the company. But if its economic incentives change, Z.AI might go back to releasing closed models.
7. Nemotron from Nvidia
Takeaway: Nvidia is an underrated open-weight developer. The Nemotron models are solid and look to be expanded soon.
Keep reading with a 7-day free trial
Subscribe to Understanding AI to keep reading this post and get 7 days of free access to the full post archives.